Pera, mas O que é um neurônio em uma rede neural? 🧠
O que é a rede neural?
Uma rede neural é uma estrutura capaz de se adaptar aos dados, buscando diminuir o seu erro. Na programação tradicional, temos uma entrada, um conjunto de regras, e o programa entrega o resultado. Por outro lado, na rede neural, nós queremos que o programa entregue o conjunto de regras de acordo com a entrada e saída conhecidos!
A rede neural será tratada com mais profundidade em outro post.
O que é o neurônio?
Um perceptron é um tipo de algoritmo de aprendizado de máquina supervisionado que pode ser usado para classificar padrões em duas ou mais categorias. Ele é chamado de perceptron porque foi inspirado na ideia de um neurônio biológico, que recebe entradas, processa essas entradas e produz uma saída.1
O neurônio, chamado de perceptron nesse contexto, é uma estrutura capaz de receber diversas informações de entrada, realizar a sua soma ponderada, e trazer o resultado disso tudo! Vamos conferir a seguir
Como funciona?
De forma semelhante à regressão linear tratada no post linkado, o perceptron recebe um vetor de entradas, que é multiplicado item a item por um vetor de pesos e soma todas as parcelas. Após a soma, é subtraído de um bias2 e esse resultado é aplicado à uma função de ativação que modela o resultado final do neurônio. A função de ativação possui diversas variações e cabe também uma postagem dedicada à ela.
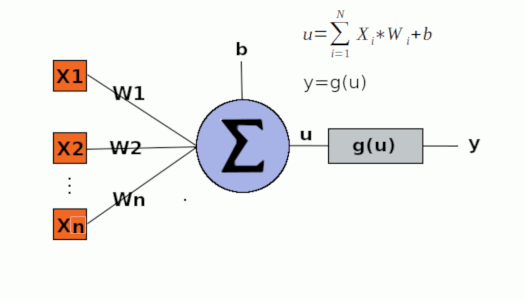
Na imagem, temos:
- Lista de entradas
x - Lista de pesos
W - Perceptron representado pela somatória
- entrada do bias
bno perceptron - A saída intermediária
u, que é o resultado da somatória subtraída do bias - A função de ativação
g, que recebeu - a saída final
y, que é a aplicação deg(u)
Uma aplicação em Python
import numpy as np
#Definindo um conjunto de dados da tabela verdade do AND
x = np.array([[0,0,1,1],[0,1,0,1]]).T #entrada
d = np.array([0,0,0,1]) #Saída esperada
def degrau(u):
return 1 if u>=0 else 0
def perceptron(entradas,pesos,funcao=degrau):
if len(entradas)==2:
entrada = [1]+entradas[:]
else:
entrada = entradas[:]
soma = np.dot(entrada,pesos)
return funcao(soma)
# Treinando
total_epochs = 10
n = 1
erro = None
peso = [b] + [z[0] for z in w]
for epoch in range(total_epochs):
for i,xk in enumerate(x):
xk = [1] + xk.tolist()
y = perceptron(xk,peso,degrau)
peso = peso+n*(d[i]-y)*np.array(xk)
# Resultado final
for c in x.tolist():
y = perceptron(c,peso,degrau)
print(c,y)
>>>[0, 0] 0
[0, 1] 0
[1, 0] 0
[1, 1] 1
Vemos que o perceptron foi capaz de aprender a regra do AND!
Obs: Esse é um exemplo simples em que temos todas as entradas possíveis, entretanto esse não é o caso comum. Mesmo sem possuir todas as entradas possíveis, o perceptron pode ser capaz de realizar boas previsões, afinal, ele é o próprio neurônio!
Notas de rodapé
-
Fornecido por https://chat.openai.com/chat ↩
-
Limiar de comparação. Constante capaz de mover a margem de classificação ↩