Como usei IA para fazer o scouting dos jogadores da Copa
Esse semestre eu peguei a disciplina de Inteligência Artificial e o trabalho do seminário era simples no enunciado e assustador na prática: escolher um tema, mostrar uma aplicação real, explicar as técnicas de IA por trás e discutir os prós e contras. O tema do meu grupo foi IA aplicada ao esporte.
Em vez de só apresentar slides sobre o assunto, a gente decidiu construir um sistema de verdade. Um pipeline que avalia jogadores de futebol a partir de dados abertos, usando as mesmas ideias que clubes como o Brentford e o Brighton aplicam no mercado da bola. A diferença é que esses clubes mantêm os modelos deles em segredo, então a gente construiu o nosso do zero, de forma transparente e reproduzível.
Esse artigo é a história de como o ICMC-Scout foi montado, bloco por bloco, e principalmente do que eu entendi sobre o que separa "rodar um modelo" de realmente entender o que está acontecendo por baixo.
O problema que o scouting tenta resolver
Scouting é o trabalho de descobrir e avaliar jogadores. Historicamente isso era feito no olho, olheiros viajando, assistindo jogos, anotando impressões. É caro, é lento e é cheio de viés. Um jogador que joga num time fraco, numa liga pequena, longe dos holofotes, simplesmente não é visto.
O grande marco da virada foi o Moneyball, lá no beisebol americano em 2002, quando um time pequeno e sem dinheiro passou a montar elenco olhando para estatísticas que o resto do mercado ignorava. A mesma lógica chegou ao futebol. O Brentford subiu da terceira divisão inglesa até a Premier League apoiado fortemente em dados, e o Brighton virou referência em comprar barato e vender caro usando modelos próprios.
A pergunta que move tudo isso é uma só: esse jogador é bom de verdade, ou só teve sorte e está sendo subvalorizado (ou supervalorizado) pelo mercado?
Onde isso se encaixa em Inteligência Artificial
Antes de escrever uma linha de código, a gente precisou deixar uma coisa clara, tanto pra gente quanto pro professor: o que aqui é IA de verdade e o que é só conta.
A hierarquia que organiza o projeto é essa:
Inteligência Artificial ⊃ Machine Learning ⊃ {supervisionado, não-supervisionado}
E a divisão ficou assim:
| Etapa | Técnica | Categoria |
|---|---|---|
| Modelo de xG | Regressão logística / Gradient Boosting | ML supervisionado, aprende com chutes rotulados como gol ou não-gol |
| Perfis táticos | K-Means | ML não-supervisionado, acha estrutura sem rótulo |
| Score final | Soma ponderada de métricas | Heurística, não é ML, são pesos que a gente definiu |
Essa separação foi proposital. Em algum momento eu cheguei a duvidar se o projeto era "IA mesmo" ou se a gente só estava fazendo estatística disfarçada. A resposta é que o coração de IA está nas duas primeiras etapas, e ser honesto sobre a terceira parte ser heurística é justamente o que dá rigor ao trabalho.
Os dados
A base é o StatsBomb Open Data, eventos detalhados de partidas reais, com a localização de cada chute, passe e ação. É gratuito e público, acessado via a biblioteca statsbombpy.
Eu usei a Copa do Mundo de 2022 (competition_id=43, season_id=106 dentro da base). São 64 partidas.
A API do StatsBomb entrega os eventos partida por partida, não em lote. Então a gente pega a lista de match_id da competição e itera, empilhando cada DataFrame numa lista:
events = pd.concat(all_events, ignore_index=True)
No fim, são 234.637 eventos, 681 jogadores que participaram de alguma jogada e 1.494 chutes na competição inteira.
Parte A: o modelo de xG (supervisionado)
O que é xG
xG, ou expected goals, é a probabilidade de um chute virar gol dado o contexto dele. Um chute de dentro da pequena área, de frente pro gol, tem xG alto. Um chute da intermediária, em cima da linha de fundo, tem xG baixíssimo. A ideia é medir a qualidade da chance, não só se a bola entrou.
Montando o dataset de chutes
Primeiro isolei os chutes, removi os pênaltis (que distorcem qualquer modelo, são chance quase isolada) e criei o rótulo is_goal, que é a resposta que o modelo supervisionado vai aprender a prever.
Mantive a coluna original shot_outcome por um tempo, só pra conferência. É uma boa prática de sanity check: você consegue olhar lado a lado e confirmar que a binarização não inverteu nada. Depois eu dropo essa coluna antes de treinar.
A taxa de conversão da base é de cerca de 11%. Isso importa muito, e vou voltar nisso na hora de avaliar o modelo, porque um modelo preguiçoso poderia simplesmente dizer "nenhum chute vira gol" e acertar 89% das vezes.
Engenharia de features
Aqui está uma das partes que eu mais gostei. A base crua não tem distância nem ângulo, ela tem só a posição do chute. Quem deriva as features é você.
Eu considerei a distância até o centro do gol e o ângulo que a baliza abre da perspectiva de quem chuta. Um chute de frente pro gol enxerga uma baliza larga. Um chute da linha de fundo, por mais perto que esteja, vê quase nada.
O campo do StatsBomb tem 120 por 80. O gol atacado fica em x = 120, com as traves em y = 36 e y = 44, ou seja, centro em y = 40. A distância sai de um Pitágoras simples:
shots['distance'] = np.sqrt((GOAL_X - x) ** 2 + (GOAL_CENTER_Y - y) ** 2)
O ângulo visado eu calculei pelo ângulo entre as retas que ligam o chute às duas traves. Além da geometria, codifiquei três sinais de contexto: cabeçada, sob pressão e origem em contra-ataque.
Como o scikit-learn trabalha com matriz numérica e não aceita True/False, tive que converter esses sinais binários. No fim, o dataset virou as duas peças que todo modelo supervisionado precisa:
feature_cols = ['distance', 'angle', 'header', 'under_pressure', 'from_counter']
X é a matriz de features (as 5 variáveis preditoras) e y é o rótulo is_goal, aquele 1 ou 0 que o modelo aprende a prever.
Treino e a importância do split estratificado
Separei os chutes em treino (onde o modelo aprende) e teste (onde a gente avalia em dados que ele nunca viu), num split de 75% e 25%.
Como só 11% dos chutes viram gol, eu usei stratify=y. Sem isso, o sorteio aleatório poderia deixar o treino com 13% de gols e o teste com 7%, distorcendo a avaliação. Forçando a mesma proporção nos dois lados:
Treino: 1.072 chutes (10,6% gols)
Teste: 358 chutes (10,6% gols)
Também fixei uma semente, RANDOM_STATE=42, declarada lá no início. O 42 é só um rótulo arbitrário pra posição de partida do sorteio. Com ele, toda vez que eu rodo o notebook o split dá o mesmo resultado, e eu consigo comparar mudanças sem que o acaso atrapalhe.
Regressão logística
Comecei pela regressão logística porque ela é simples, rápida e fácil de interpretar. Ela me diz, pelo sinal de cada coeficiente, em que direção cada feature empurra a probabilidade de gol.
logreg = LogisticRegression(max_iter=1000, random_state=RANDOM_STATE)
logreg.fit(X_train, y_train)
O .fit() é onde a mágica acontece. O modelo ajusta os coeficientes pra melhor mapear as features no rótulo. A regressão logística não tem fórmula fechada, ela acha os pesos por otimização iterativa: o solver vai refinando passo a passo até convergir.
Pensa que existe uma combinação ideal de pesos lá fora, e o trabalho do treino é encontrá-la por tentativa e erro inteligente. O max_iter=1000 é dizer "dá no máximo mil passos". Se o solver chega no fundo do vale em 300 passos, ele para sozinho. Se bate em mil e ainda não chegou, ele para por esgotar o limite e o sklearn avisa que não convergiu. O padrão é 100, subir pra 1000 é dar mais fôlego.
Um detalhe que me pegou: features em escalas muito diferentes deixam esse vale deformado e o solver precisa de mais passos. A distance vai de 0 a uns 60, o angle de 0 a uns 3. Essa diferença de escala faz o caminho até o melhor valor ser mais tortuoso.
O resultado bateu com a intuição de futebol, o que foi o melhor sanity check possível:
- Cabeçada reduz a chance de gol. Faz sentido, cabeceio tem menos potência e precisão que chute de pé.
- Sob pressão, menos gol. Correto.
- Quanto mais longe, menos gol. Correto.
- Contra-ataque aumenta a chance, defesa desorganizada gera chance mais limpa. Correto.
- Ângulo mais aberto, mais chance. Correto.
Os cinco coeficientes apontam pra direção que qualquer analista esperaria. Vale notar que header tem o valor mais negativo porque é binário, então o coeficiente é o efeito total de ser cabeçada contra não ser. Já a distance é contínua em metros, então o coeficiente é o efeito de cada metro a mais.
A limitação dela é que a regressão logística é linear, ela assume que cada feature soma seu efeito de forma independente. Mas o futebol tem interações: a distância importa de um jeito diferente dependendo do ângulo.
Gradient Boosting
Pra atacar essa limitação, treinei um Gradient Boosting. Ele combina centenas de pequenas árvores de decisão, cada uma corrigindo os erros da anterior. A primeira árvore faz uma previsão grosseira, o modelo olha onde ela errou, a segunda foca em corrigir esses erros, a terceira corrige o que sobrou, e assim por diante.
GradientBoostingClassifier(n_estimators=200, max_depth=3, learning_rate=0.1)
Três escolhas que parecem estranhas no começo: n_estimators=200 são 200 árvores em sequência. max_depth=3 deixa cada árvore rasa de propósito, porque no boosting você quer aprendizes fracos. Se cada árvore já fosse poderosa, ela decoraria o treino sozinha e o conjunto faria overfit. learning_rate=0.1 faz cada árvore contribuir só com 10% da correção que faria, passos pequenos evitam que uma única árvore puxe tudo pra direção errada.
De bônus, o Gradient Boosting entrega de graça um ranking de importância das features, respondendo aquela pergunta que ficou aberta na logística: qual variável pesa mais?
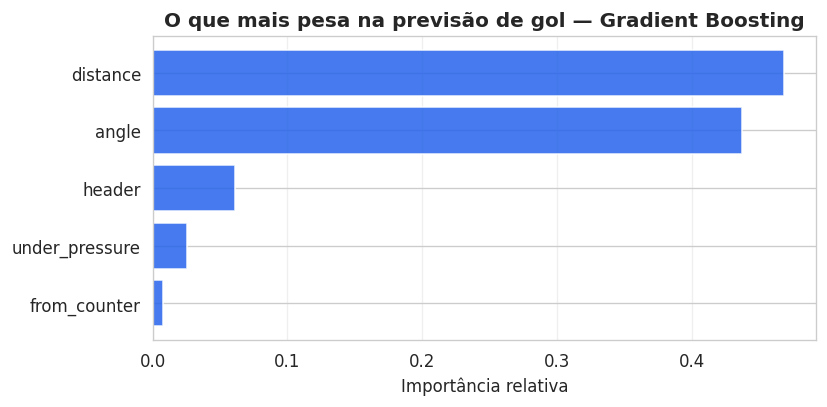
O gráfico mostra uma coisa bonita e bem clara: o modelo de xG é, na essência, geométrico. Distância e ângulo dominam, header, pressão e contra-ataque são detalhes. É exatamente o que a literatura de xG diz há anos.
Avaliação: treinou não é a mesma coisa que é bom
Aqui está o ponto mais importante de toda a parte supervisionada. "Treinou" não quer dizer "é bom". Avaliei os dois modelos no conjunto de teste, chutes que nenhum deles viu.
E não usei acurácia. Como só 11% dos chutes viram gol, um modelo que dissesse "nunca é gol" acertaria 89% e seria completamente inútil. Usei três métricas mais honestas:
- Log-loss (menor é melhor): pune previsão confiante e errada. Se o modelo diz "90% de gol" e não é gol, leva punição pesada.
- ROC-AUC (maior é melhor): mede se o modelo sabe ordenar, se ele dá xG mais alto pros chutes que viraram gol. 0,5 é chute no escuro, 1,0 é separação perfeita.
- Brier (menor é melhor): o erro quadrático médio entre o xG previsto e o que aconteceu. Mede o quão perto o número bateu com a realidade.
Cada modelo cospe a probabilidade de cada chute virar gol via predict_proba(...)[:, 1], e o resultado foi:
Log-loss ROC-AUC Brier
Regressão Logística 0.2776 0.8108 0.0819
Gradient Boosting 0.3049 0.7972 0.0919
A parte mais visual da avaliação é a curva de calibração. A pergunta é direta: quando o modelo diz "0.3 de xG", esses chutes viram gol perto de 30% das vezes na vida real?
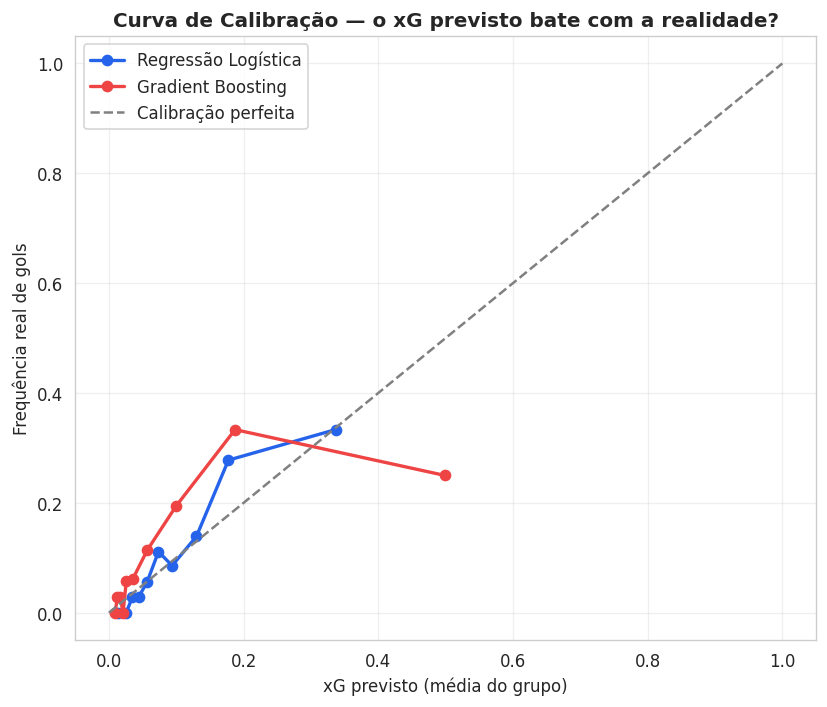
O código agrupa os chutes em 10 faixas de xG e compara, em cada faixa, o xG médio que o modelo previu contra a fração que de fato virou gol. A diagonal tracejada é o ideal, previsto igual a realidade. Se a curva gruda na diagonal, o xG é confiável. Acima da linha, o modelo subestima. Abaixo, superestima. Pra xG isso é crucial, não basta ordenar certo, o número 0.3 tem que valer 0.3.
Por que o modelo mais simples ganhou
A regressão logística ganhou nas três métricas. E isso me ensinou algo que eu não esperava: modelo mais poderoso não é sempre melhor.
O Gradient Boosting brilha quando há relações complexas e não-lineares e muito dado pra alimentá-lo. Mas a relação do xG é suave e monotônica, mais distância significa menos gol de forma contínua e previsível. A logística modela isso com perfeição, é literalmente o formato pra que ela foi feita. O Gradient Boosting, com poucos dados de uma única copa, acabou dando confiança demais em chutes de alto xG e a bola não entrou na proporção prometida. Aquela queda da curva vermelha abaixo da diagonal no canto é o modelo mentindo sobre as melhores chances.
Aplicando: o xG por jogador
Com a logística escolhida, calculei o xG de cada chute do dataset inteiro e somei por jogador. Aqui não tem métrica de performance sendo medida, eu só quero o melhor xG possível pra cada chute pra poder agregar.
E aí nasce a métrica-chave: gols reais menos xG esperado, o famoso G menos xG.
- Positivo, converteu mais do que as chances mereciam (bom finalizador, ou sortudo).
- Negativo, desperdiçou chances.
Isso me deu dois rankings que respondem perguntas diferentes. O maior xG acumulado mede volume de perigo criado, quem chega em boas posições de chute com frequência. A finalização acima do esperado mede eficiência, quem converte além do que a posição previa. Um jogador pode liderar um ranking e nem aparecer no outro.
Pra finalização eu filtrei só quem teve mais de 5 chutes. Sem esse piso, um zagueiro que deu 1 chute e fez 1 gol apareceria com overperformance altíssima e lideraria os finalizadores, puro ruído. Para ser honesto, 5 é um piso fraco, numa copa um jogador faz de 10 a 30 chutes no torneio todo, e essa é uma das limitações que eu reconheço no projeto.
Parte B: perfis táticos (não-supervisionado)
Aqui muda a natureza do problema. Não existe rótulo, ninguém me diz o "estilo certo" de cada jogador. O trabalho é deixar o algoritmo achar estrutura sozinho.
Métricas por 90 minutos
Resumi cada jogador num vetor de métricas táticas: passes-chave, passes progressivos, precisão de passe, pressões, recuperações, conduções, taxa de drible, taxa sob pressão e o xG por 90, esse último vindo do meu próprio modelo, não do StatsBomb.
Normalizei tudo por 90 minutos pra comparar quem jogou muito com quem jogou pouco de forma justa. Também removi os goleiros, 41 deles, porque eles bagunçavam os grupos. Sobraram 314 jogadores qualificados.
Matriz de correlação antes de agrupar
Antes de jogar as métricas no K-Means, explorei como elas se relacionam. A ideia é garantir que cada métrica traz informação nova.
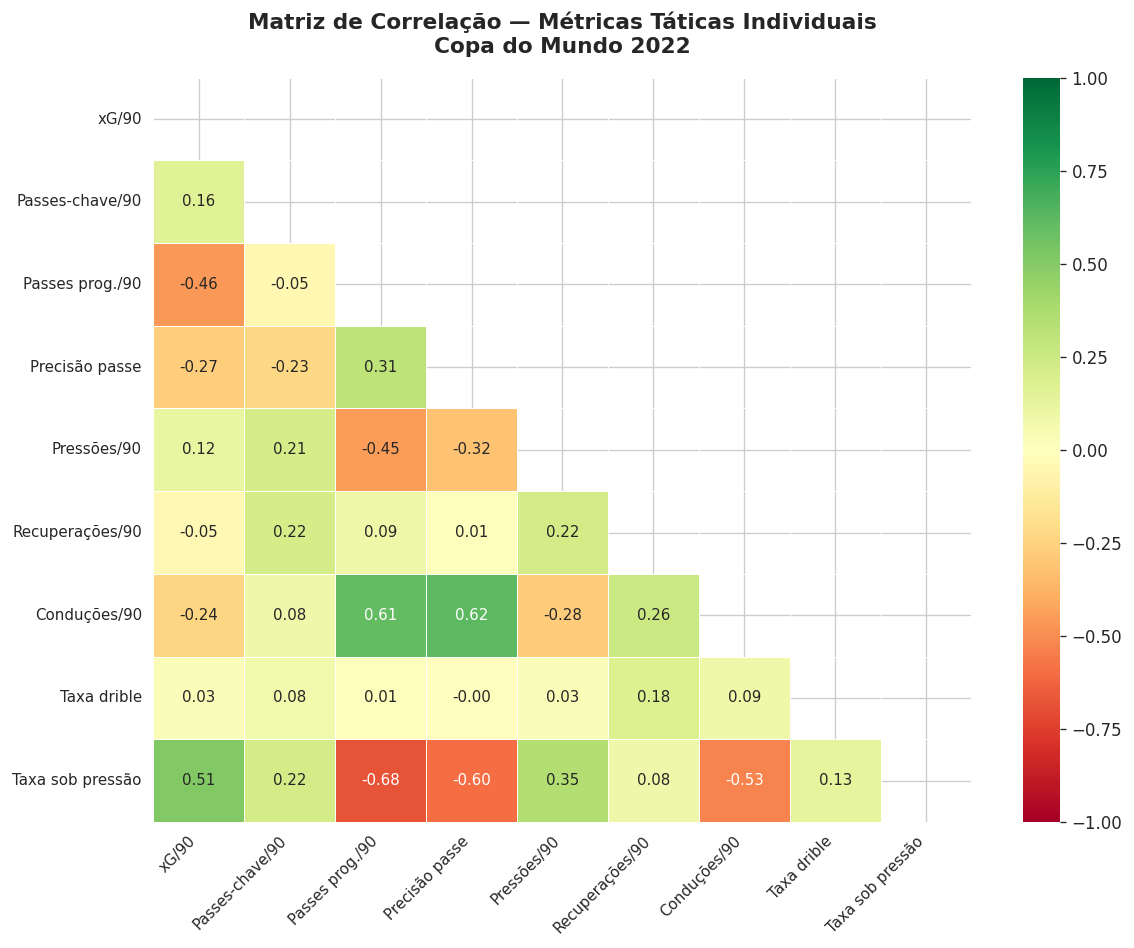
Correlação perto de +1 quer dizer que as duas sobem juntas e medem quase a mesma coisa. Perto de 0, são independentes. Se duas métricas fossem quase idênticas, o K-Means daria peso dobrado àquela dimensão sem querer e distorceria os grupos.
O bonito é que as correlações ficaram em geral baixas, o que valida usar todas. E alguns pares que poderiam parecer redundantes mostraram que não são: quem faz gol não é necessariamente quem dá o passe pro gol (artilheiro contra armador), pressionar muito não garante recuperar a bola, e quem conduz muito não é quem dribla melhor.
K-Means
O K-Means olha os jogadores como pontos num espaço (cada métrica é uma dimensão) e agrupa os que estão próximos entre si, por pura semelhança matemática, sem ideia nenhuma do que cada grupo significa.
Como ele mede distância, todas as métricas precisam estar na mesma escala, então apliquei StandardScaler antes. Escolhi quatro grupos por interpretabilidade. Estilos de jogo são um espectro contínuo, não caixas isoladas, então o que valida a escolha não é uma separação estatística perfeita e sim o quanto cada perfil faz sentido. Os quatro arquétipos que surgiram foram Construtor, Criador de jogo, Finalizador puro e Polivalentes.
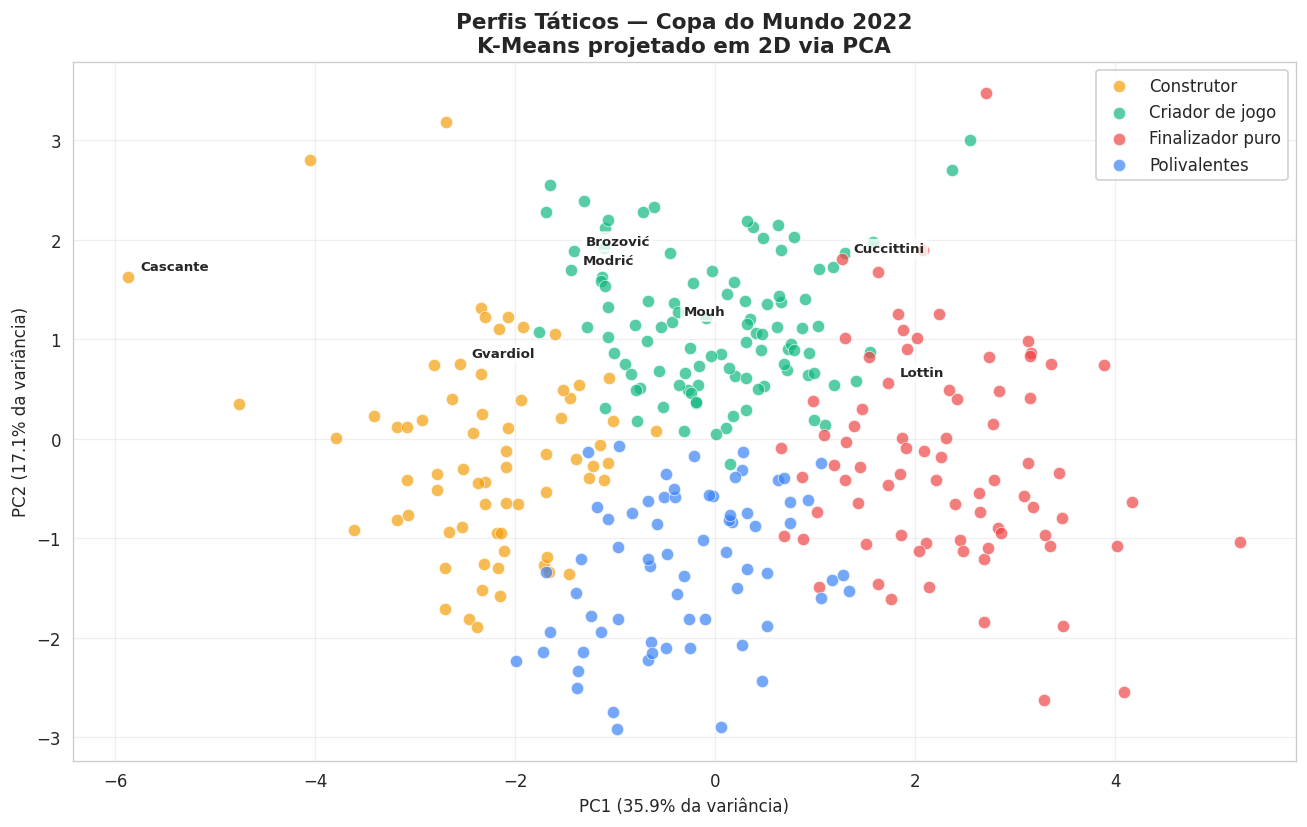
Vale uma confissão metodológica aqui: eu cheguei a olhar silhouette e elbow pra escolher o K, e eles não apoiavam K=4 de forma limpa. Troquei esses gráficos por um heatmap de centroides, que mostra a assinatura de cada perfil, porque pra estilo de jogo a interpretabilidade conta mais do que um número de corte. Foi uma decisão consciente, não um detalhe varrido pra debaixo do tapete.
Os radares
Pra mostrar na prática o que cada perfil significa, transformei cada jogador num gráfico de radar, uma espécie de impressão digital tática. Cada ponta é uma habilidade (finalização, passe-chave, progressão, pressão, recuperação, drible) e quanto mais perto da borda, mais o jogador se destaca naquilo. Normalizei pelo top 5% da copa, então encostar na borda significa estar em nível de elite do torneio naquela métrica.
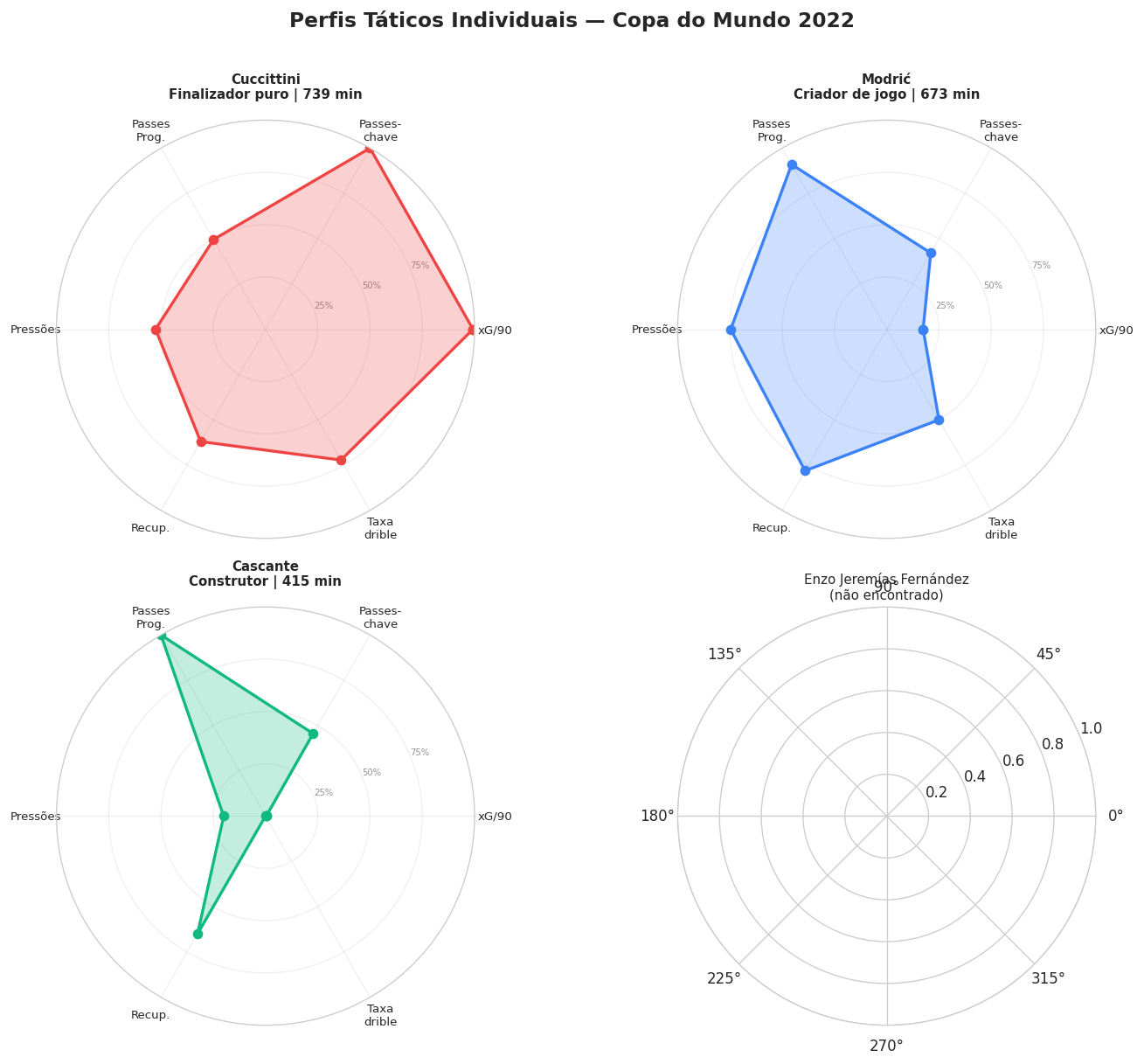
Olhando os radares lado a lado, dá pra ver na hora que são jogadores diferentes, um finalizador tem um formato, um criador tem outro, um construtor tem outro. O clustering achou isso sozinho, sem nunca saber a posição de ninguém.
Parte C: integração e shortlist (ICMC-Scout)
A última parte junta tudo, o xG supervisionado da Parte A e os perfis não-supervisionados da Parte B, numa camada de saída que apresenta os resultados. Aqui já não é mais ML, é integração e heurística, e eu faço questão de deixar isso explícito.
A tese de scouting por trás da shortlist é a parte de que mais me orgulho. As métricas usadas são todas de impacto sem gol: criação, progressão, defesa, condução. O gol não conta de propósito. Quem faz gol todo mundo vê e todo mundo valoriza, então não tem pechincha ali. O sistema foca no contrário, no trabalho invisível que não aparece no placar.
E o pulo do gato: cada jogador é comparado só com os parecidos com ele, dentro do próprio perfil tático que o clustering criou. Comparar um volante com um meia-atacante seria injusto. Comparando dentro do grupo, eu pergunto "esse jogador se destaca entre os iguais a ele?", e isso vira a nota de destaque no perfil (um z-score ponderado).
Os filtros finais resumem a tese:
- xG abaixo da média, ou seja, não chama atenção pelos gols.
- Pelo menos 3 jogos completos, pra não ser sorte de quem jogou pouco.
- Não é atacante puro, porque o valor de um atacante é o gol, não faz sentido procurá-lo aqui.
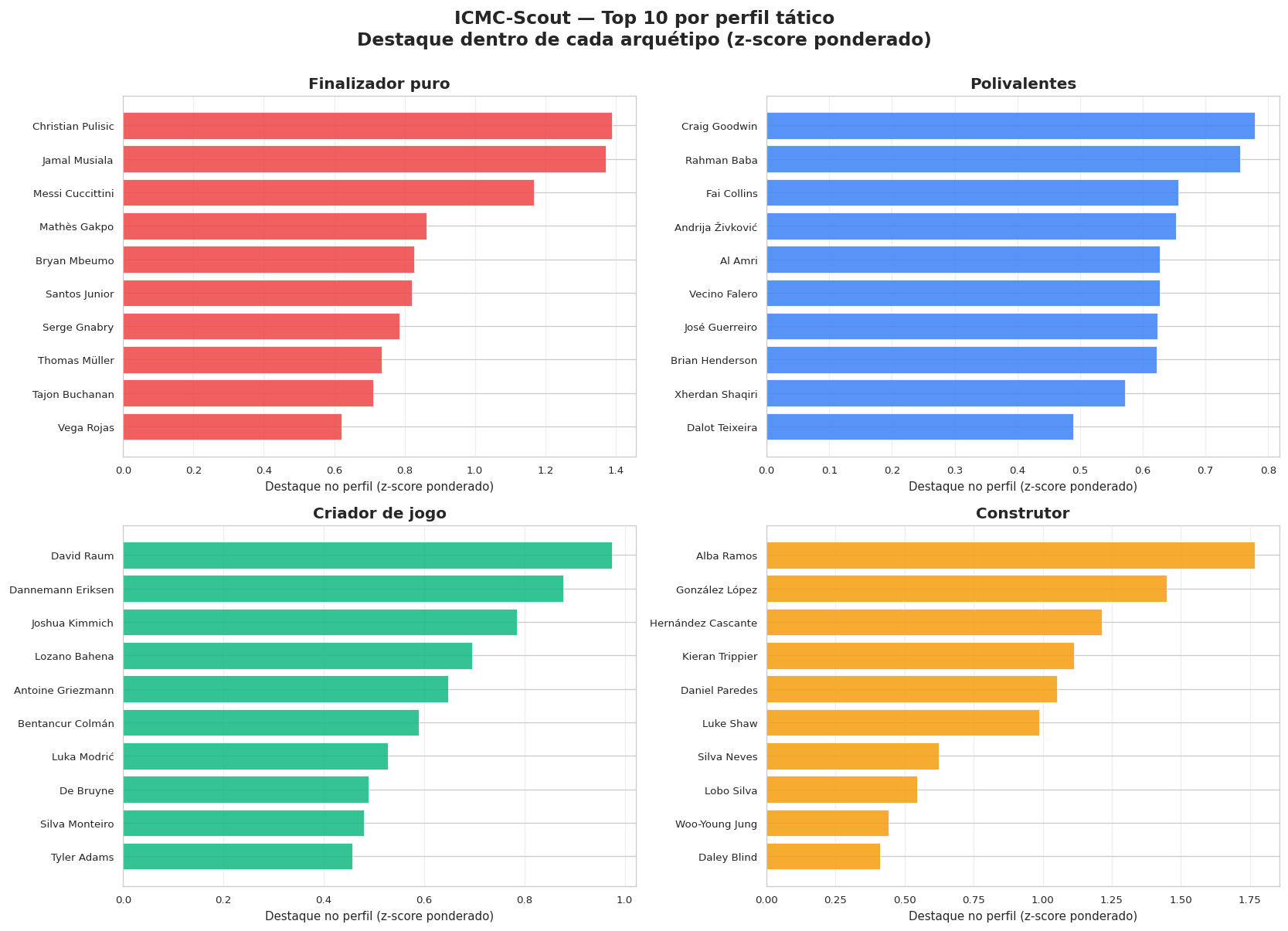
O resultado é uma lista de jogadores que fazem muito pelo time de formas que o placar não mostra, cada um comparado com os do mesmo estilo. É o ICMC-Scout fazendo, em pequena escala e com dados abertos, o que os clubes fazem a portas fechadas.
Fontes e ferramentas: StatsBomb Open Data (statsbombpy), scikit-learn, pandas e numpy. O contexto de scouting orientado a dados se apoia no histórico do Brentford e do Brighton e na lógica do Moneyball aplicada ao futebol.