Implementando uma Binary Search Tree 🌲
Hoje eu quero demonstrar uma implementação de uma binary search tree. Essa estrutura de dados é fundamental e muito comum no dia a dia dependendo do seu nicho.
Para quem não sabe, uma Tree é uma estrutura de dados que organiza os elementos de forma hierárquica, como demonstrado abaixo:
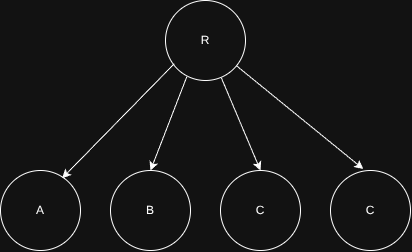
O primeiro node é o root e os outros são seus filhos children. Lembre-se deste dois termos, eles são importantes para praticamente todas as árvores.
A imagem acima demonstra apenas uma Tree genérica. Uma Binary Search Tree é um sabor específico de Tree. Veja abaixo:
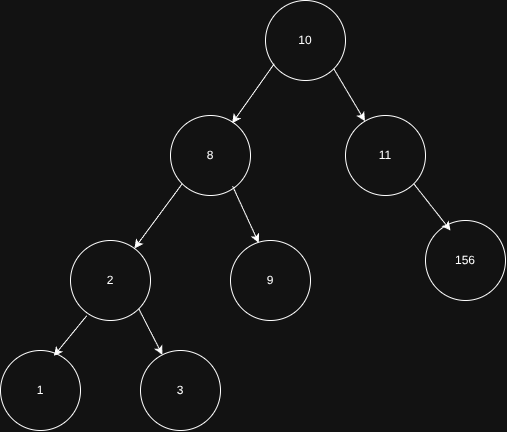
Na imagem podemos ver uma mesma estrutura tree, mas com detalhes interessantes.
Cada node tem no máximo dois children. Nunca mais. Além disso os números em cada node diz bastante também. Do lado esquerdo temos números menores que o root. No direito temos maiores que o root. Nos filhos de root o mesmo se repete. Isto também é uma regra.
Em uma Binary Search Tree, supondo que temos um node qualquer chamado X, a sua esquerda fica um valor menor que X, e a sua direta maior que X.
Podemos observa na imagem que, o root tem um valor de 10, e sua esquerda tem um valor de 8. Já a sua direita temos um valor de 11. E o padrão se repete. Outro ponto a se notar é que não temos nodes com valore repetidos. Isto não é uma regra, mas é muito comum simplesmente ignorar valores repetidos.
Detalhes sobre a implementação
A implementação estará em Rust, mas obviamente é possível implementar em todas as linguagens mais populares.
Um detalhe importante é para quem program em C e C++. É muito provável que a implementação nessas linguagens sejam bem diferente por questões de gerenciamento de memória então fiquem atentos a isto.
Eu só irei implementar os métodos essenciais. A ideia não é criar algo que vai para produção, mas sim algo que irá transmitir conhecimento. A partir disto você poderá re-implementar isso como quiser.
Eu irei utilizar tree para me referir a uma Binary Search Tree a partir de agora.
Definindo a estrutura da árvore
Agora nós iremos definir a estrutura da tree, começamos com o seguinte código:
struct Node<T: Ord + Clone> {
element: T,
left: Option<Box<Node<T>>>,
right: Option<Box<Node<T>>>,
}
Um struct é como um object em muitas linguagens, mas em Rust tem suas particularidades. Particularidades essas que são irrelevantes neste post.
Temos um field element que irá conter algum valor genérico sobre o tipo T. Este valor genérico precisa ter a capacidade de ordenação como i32, u32 e outros valores que podem ser ordenados e comparáveis. Isto é bem intuitivo.
Ignore o
Clone, pois ele é uma funcionalidade que desrespeito a implementação em Rust, mas não a implementação em si.
Os fields left e right irão armazenar os seus filhos da mesma forma que vimos na imagem. Em Rust Option é usado para indicar a presença e ausência de valores. Em JavaScript você poderia utilizar null no lugar. Box indica que o valor seŕa armazenado na heap por questões de gerenciamento de memória inerente ao Rust.
Apesar de
OptioneNullrepresentarem a presença e ausência, eles são bem diferentes, mas foge do escopo essa explicação.
pub struct BST<T: Ord + Clone> {
root: Option<Box<Node<T>>>,
}
Este é um wrap que eu criei para os nodes. É literalmente um field que contém o root que pontua para todos os outros. Isto foi necessário por eu estar implementando em Rust, então você provavelmente não precisará se preocupar com isto.
Agora temos uma estrutura que armazena um valor, seus filhos a esquerda e direita. Iremos agora começar a implementar algum comportamento.
Inserindo nodes
Detalhe importante: Eu criei uma interface publica para BST que chama os métodos de Node para deixar mais "limpo" o código. Então para os dev Rust, não se se espante com a false de &self daqui para frente.
Para criar um novo node na árvore, é muito simples. Começamos do root, e vamos comparando com o valor atual com o que queremos inserir. Se o valor que queremos inserir for maior, fazemos uma chamada recursive com o node a direita do valor atual, pois é na direita que são inserido os nodes de valor mais alto. Fazemos o mesmo para caso for menor, só que para a esquerda. Quando a chamada recursiva alcançar algum None, significa quen não existe um node ali, então encontramos lugar para inserir o nosso mais novo node.
Vamos considerar que eu tenho um root com o valor de 10, então eu quero adicionar o número 50:
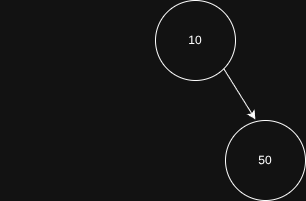
Nosso método precisa comparar o 50 com o valor do node atual, que neste caso é 10, e então fazer a chamada recursiva correspondente. Neste caso, como 50 é maior que 10, devemos obter o filho da direita de 10 e chamar insert novamente. No entanto, como não há nada ali, chegamos no local adequado para inserir o novo valor.
Vamos inserir o valor de 49 agora:
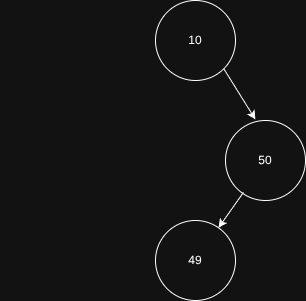
- Primeiro ocorre a comparação de 49 com o valor 10.
- 49 é maior que 10, então chamamos o método insert com o node da direita
- 49 é comparado com 50
- 49 é menor que 50
- Invocamos o método
insertcom o node a esquerda de 50. - Nada é encontrado, portamos inserimos o node 49 ali.
fn insert(node: &mut Option<Box<Node<T>>>, element: T) {
if let Some(node) = node {
match element.cmp(&node.element) {
std::cmp::Ordering::Equal => (),
std::cmp::Ordering::Greater => Self::insert(&mut node.right, element),
std::cmp::Ordering::Less => Self::insert(&mut node.left, element),
}
} else {
*node = Some(Box::new(Node {
element,
left: None,
right: None,
}))
}
}
Em Rust há um método incrível chamad cmp que compara um valor X com Y e retorna um Enum de acordo com o resultado, que são os Less, Equal e Greater. Com base nisso eu determino o que fazer com o valor. Você provavelmente terá de fazer a comparação com operadores lógicos como >, < e ==.
Quando o valor é equivalente, ou seja Equal, o valor é ignorado silenciosamente, retornando ().
Encontrando o valor mínimo e o valor máximo
Este dois métodos são muito simples. Eu só preciso percorrer toda a árvore a esquerda ou direita para encontrar uma leaf. Uma Leaf é um node cujo não tem filhos.
fn find_min(node: &Option<Box<Node<T>>>) -> Option<T> {
let node = node.as_ref()?;
match &node.left {
Some(_) => Self::find_min(&node.left),
None => Some(node.element.clone()),
}
}
fn find_max(node: &Option<Box<Node<T>>>) -> Option<T> {
let node = node.as_ref()?;
match &node.right {
Some(_) => Self::find_max(&node.right),
None => Some(node.element.clone()),
}
}
eu verifico se o node existe, pois a arvore pode estar vazia, então se existir, eu verifico se o seu filho a esquerda existe. Se existe, então esse não é o menor valor pois nós sabemos que o valor mais a esquerda da árvore é o menor. O mesmo é verdade para encontrar o maior valor.
Verificando se um node existe:
fn contains(node: &Option<Box<Node<T>>>, element: T) -> bool {
match node {
Some(n) => {
match element.cmp(&n.element) {
std::cmp::Ordering::Equal => true,
std::cmp::Ordering::Greater => Self::contains(&n.right, element),
std::cmp::Ordering::Less => Self::contains(&n.left, element)
}
},
None => false
}
}
Muito simplesmente de implementar. Basta comparar o valor que eu quero encontrar, por exemplo, 50, e comparar esse 50 com o atual valor que tenho. Se for less ou greater, eu faço uma chamada recursiva para a esquerda o direita até que encontre um equal. Se por ventura None for retornado antes, então o elemento não existe.
Removendo nodes
O método mais difícil de implementar neste exemplo. Isto me custou cerca de 30 horas no total incluíndo pausas para atingir o resultado esperado. Como eu estava com tempo livre, não foi problema.
Para remover um node em uma binary search tree, é necessário considerar 3 cenários.
- O node que eu quero remover X tem dois filhos, então eu preciso pegar o menor elemento a direita do valor Y que eu quero remover, pegar esse valor, substituir o valor de X por Y.
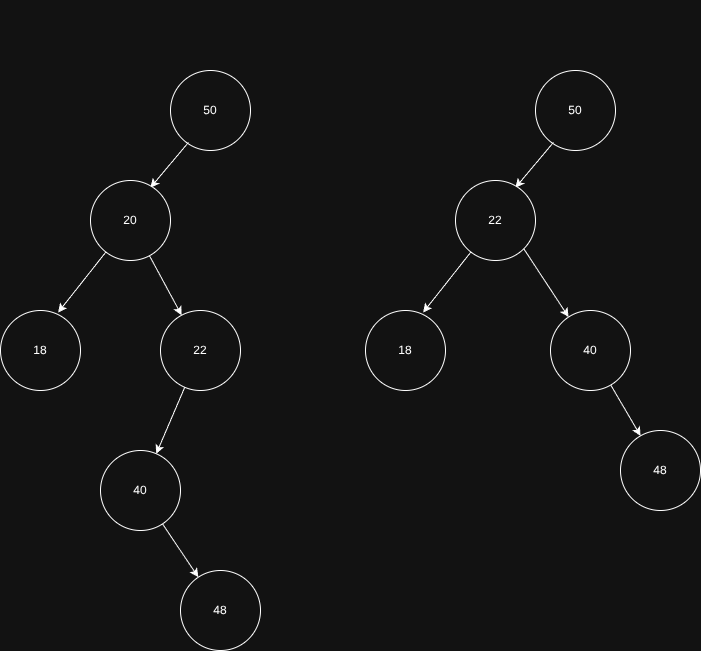
A esquerda é antes de remover, a direita é depois de remover. Observe que o 22 substituiu o 20.
O menor a direita de 20 é 22, então esse valor substitui 20, e obviamente, quando atribuímos um novo node ao node 20, os filhos do novo node vêm juntos pois o struct tem referência recursiva para si mesmo com valores diferentes.
Outro ponto importante é que, normalmente copiamos o node 22 e atribuímos ao 20. Neste caso teriamos uma árvore que contém 22 duas vezes. Para evitar isso fazemos uma chamada recursiva para apagar o valor duplicado.
-
O segundo caso é o mais simples. Se o node tiver um único filho, devemos simplesmente linkar o filho com o "avó".
-
Se é uma leaf, então simplesmente apagamos
fn remove(node: &mut Option<Box<Node<T>>>, value: T) {
let node_val = node.as_mut().unwrap();
match value.cmp(&node_val.element) {
std::cmp::Ordering::Greater => Self::remove(&mut node_val.right, value),
std::cmp::Ordering::Less => Self::remove(&mut node_val.left, value),
std::cmp::Ordering::Equal => {
let right = node_val.right.is_some();
let left = node_val.left.is_some();
match (left, right) {
(true, true) => {
let sucessor = Self::find_min(&node_val.right).unwrap();
node_val.element = sucessor.clone();
Self::remove(&mut node_val.right, sucessor);
},
(false, true) => *node = node_val.right.take(),
_ => *node = node_val.left.take(),
}
},
}
}
Primeiro comparamos o valor que queremos remover com o atual até encontrar ele. Se não encontrar esse valor não existe e falha silenciosamente.
Quando o valor é encontrado eu verifico se o node a esquerda e direita existe com is_some(). Isto retorna valores boolean (padrão de métodos com "is" em sua signature).
Então eu testo uma tupla (left, right) e testo contra alguns padrões esperados.
Se tiver dois filhos, ou seja (true, true), obtemos o sucessor que é valor mínimo a direita de X (O node a ser removido). Então atualizamos o seu valor, e chamamos novamente remove para apagar o valor duplicado.
Se tiver um único filho a direita, eu pego a propriedade (ownership) do filho de X com o método take, deixando None no lugar e atualizo X para ser seu filho obtido Y.
O mesmo ocorre com a esquerda na condição _ que engloba todo os outros padrões possíveis. Se tiver um filho a esquerda, ele é obtido e o no X se torna ele, se não tiver nada, ou seja None, eu pego o None e atualizo o node da mesma forma.
Conclusão
Foi uma aventura implementar essa estrutura. Eu não sei se expliquei bem. Se tiverem dicas ou reclamações, fique a vontade. Adoro ouvir críticas pois somente com elas podemos melhorar!