Por que você deveria entender de gerenciamento de memória no React Native

Ultimamente vejo um número cada vez mais crescente de pessoas ingressando na área de desenvolvimento de software. Há neles um entusiasmo nítido em relação ao uso de ferramentas e frameworks e uma total falta de profundidade em relação aos fundamentos da computação (posso dizer que isso não se restringe aos novatos). Assuntos como processos e threads, concorrência e paralelismo, memória, sistema operacional e suas abstrações, análise de algoritmos e paradigmas de programação, para citar somente alguns exemplos, permeiam toda a vida útil de um software e entretanto não são abordados com a ênfase que deveriam.
Não busco tecer uma crítica nesse artigo. Essa introdução visa somente chamar a atenção para um tópico importante e introduzí-los ao assunto que de fato irei descorrer aqui: devemos nos preocupar com os fundamentos da computação para que possamos criar softwares melhores.
Com essa preocupação em mente, trago um assunto negligenciado por muitos desenvolvedores que trabalham com React Native (isso extende a outras linguagens e frameworks também). Não pretendo dar uma aula de gerenciamento de memória. O que fiz aqui foi sintetizar alguns pontos importantes dessa área da computação a fim de lhes prover o mínimo necessário para começar a se preocupar com esses conceitos quando estiver escrevendo a sua aplicação.
Dito isso, vamos analisar como a memória na maioria dos computadores funciona e como podemos obter uma melhor perfomance dela em aplicativos React Native.
Diferença entre Stack e Heap
Quando um programa é iniciado por um sistema operacional ele recebe alguns espaços para alocação de dados. Esses espaços, disponibilizados pela memória principal, são organizados por área e função. Dentre essas áreas, duas se destacam: Heap e Stack. Essas duas áreas são espaços de endereçamento cuja dinâmica difere em alguns pontos substanciais.
Heap

O Heap é uma área de alocação dinâmica, não ordenada e é a organização de memória mais flexível, o que permite o uso de qualquer área lógica disponível. Seu espaço é reservado para alocação de dados e variáveis criados durante a execução do programa. Em outras palavras, podemos alocar ou desalocar pequenos trechos de memória de acordo com a necessidade do dado. Caso o limite reservado seja atingido, é possível solicitar mais memória ao SO por meio de syscalls (chamadas ao sistema).
Um ponto importante a ser considerado no contexto do Heap é que se houver uma frequência de alocação/desalocação muito alta, pode haver fragmentação de memória. Isso gera impacto na performance e na eficiência de como o programa aloca memória. Para evitar problemas desse tipo, o SO utiliza um mecanismo chamado "página", que a grosso modo é um bloco de tamanho fixo disponibilizado para alocação de dados.

A desalocação da memória pode ser feita de mais de uma forma, sendo mais comum as seguintes:
- Quando o programa é encerrado
- Manualmente (quando a linguagem de programação permite)
- Através de um Garbage Collector
Um Garbage Collector basicamente varre a memória em busca de dados que não serão mais usados e então os descarta. Discutiremos sobre ele mais a frente.
É válido mencionar ainda que o sistema operacional faz uso de um conceito chamado memória virtual para gerenciar o Heap (assunto para um outro artigo).
Stack (pilha)

Diferente do Heap, a Stack (pilha) é uma organização otimizada da memória para alocação de dados em sequência. Aqui, é normal nos depararmos com confusões acerca da sua definição. Embora muitos pensem que a pilha de funções é a mesma coisa que a pilha de memória, na verdade, são duas entidades diferentes. A diferença fundamental é que a pilha de funções armazena a sequência de chamadas dos blocos de código, enquanto a pilha de memória armazena os dados (também em sequência e em áreas chamadas stack frames) relacionados ao escopo das funções (como parâmetros, variáveis locais e retorno de funções).
A pilha funciona no formato LIFO (Last in First Out) ou UEPS (último a entrar, primeiro a sair). Quando a execução de um bloco de código (ou função) termina, todo o stack frame é desalocado da pilha e os seus dados são descartados. Ou seja, as variáveis da pilha só existem enquanto a função que as criou estiver em execução - já tentou acessar uma variável de fora da função que a criou?. Como podemos perceber, não há fragmentação de memória aqui, dado a natureza e a configuração da pilha.

Outra diferença importante em relação ao Heap é o tamanho da pilha. A stack costuma ter um limite mais rídigo, configurado durante a inicialização do programa. Esse limite de tamanho normalmente é controlado pelo runtime da linguagem junto com o sistema operacional. Assim sendo, se a pilha atiginir o seu limite, iremos nos deparar com um erro de stack overflow e o programa será encerrado.
Por último, mas não menos importante, o acesso aos dados na Stack costuma ser mais rápido que no heap, dado que o acesso é direto e preciso.
Gerenciamento de memória no Android

No sistema operacional Android (escrito em JAVA), se um aplicativo atingir a capacidade de Heap e tentar alocar mais memória, ele poderá receber uma mensagem de OutOfMemoryError. Para ajudar a prevenir esse tipo de problema e gerenciar a memória com mais eficiência (isto é, desalocar a memória para liberar espaço e otimizar a performance do sistema) o SO da Google faz uso de um mecanismo chamado Garbage Collector.
Garbage Collector
O Garbage Collector é um processo em segundo plano que constantemente revisa objetos e módulos e desaloca memória daqueles que não são referenciados direta ou indiretamente. Em outras palavras, quando um objeto é criado, ele recebe o que é chamado de contagem de retenção ou contagem de referência e representa o número de entidades que fazem referência aquele objeto. Esse número de refêrencias é usado pelo GC como critério de desalocação e caso a referência seja zero, ele automaticamente irá coletar o dado e liberar o seu espaço.
A coleta ocorre de tempos em tempos e é considerada não determinística, ou seja, não é possível controlar quando um evento de coleta de lixo ocorre no código. O próprio sistema tem um conjunto de critérios para determinar quando a coleta de lixo deve ser feita.
Vale ainda ressaltar que durante a coleta o desempenho e processamento das nossas aplicações pode ser afetado, principalmente quando altas cargas de trabalho estão sendo executadas (ex. animações). Por isso é extremamente importante projetarmos bem o nosso software, pois se um código não for bem escrito, o seu fluxo pode forçar os eventos de coleta a ocorrer com mais frequência ou durar mais tempo que o normal.
Mais a frente veremos que mesmo o GC não blinda a nossa aplicação de sofrer problemas de memória, como os temidos vazamentos.
Gerenciamento de memória no IOS

As principais linguagens de programação dos aplicativos IOS é Objective-C e Swift. Essas duas linguagens, diferente do Android e JAVA, não fazem uso de um Garbage Collector para gerenciar recursos de memória. Ao invés desse mecanismo, é usado um sistema determinístico e parcialmente manual chamado ARC.
ARC (Automatic Reference Count)
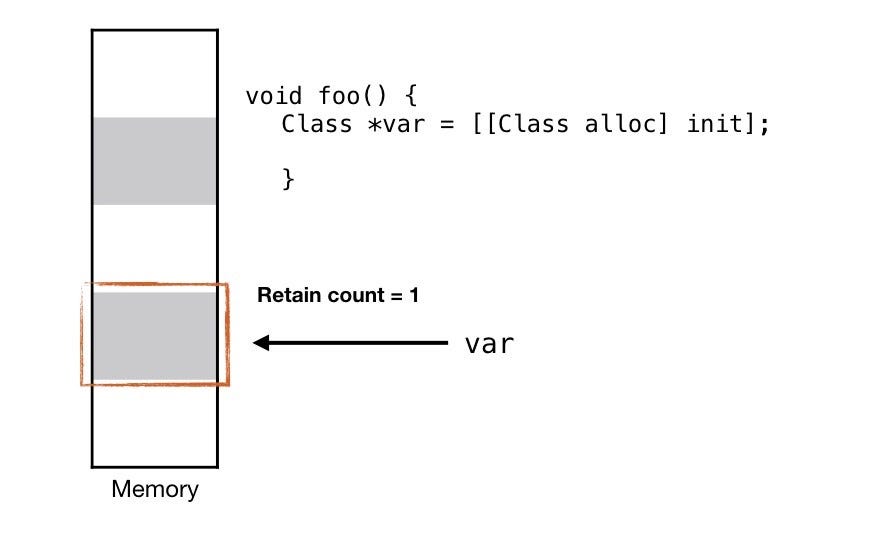
Antes do surgimento do ARC, o programador precisava manualmente fazer o release dos objetos via código, isto é, a coleta e liberação de memória. Basicamente, o programador tinha que imaginar todos os cenários lógicos possíveis pelos quais o app passaria para garantir um tempo de vida adequado ao objeto (loucura não?!). Porém, com o ARC, o compilador se responsabiliza por essa tarefa e ele mesmo faz a contagem e coleta.
Dito isso, podemos concluir que em aplicativos desenvolvidos usando a linguagem Objective-C e Swift, o próprio código determina quandos os objetos devem ser liberados da memória.
React Native usa GC ou ARC?
Bom, já vismo que o gerenciamento de memória é diferente entre dispositivos IOS e Android. Porém, cabe uma excelente pergunta: como funciona o gerenciamento de memória no React Native?
A resposta é: Garbage Collector!
Antes de tudo, é importante dizer que o gerenciamento de memória não é realizado somente pelo sistema operacional. As linguagens que usamos para construir os nossos programas também possui esse papel, visto que no final das contas, todo o código que escrevemos será compilado para código de máquina por meio de ferramentas da própria linguagem de programação.
Quando trabalhamos com o React Native, escrevemos código utilizando Javascript. No entanto, o arquivo javascript final (comumente conhecido como bundle) não é transpilado para uma linguagem nativa (como JAVA no Android ou Swift no IOS). Na verdade o bundle.js é executado no JavaScriptCore - uma máquina virtual otimizada que habita numa única thread do SO - , que é responsável por compilar o código Javascript em código binário.
Em programas escritos com Javascript, o gerenciamento de memória é feito automaticamente por meio de um Garbage Collector, cujos princípios já foram discutidos acima.
Um ponto interessante aqui é que a maior parte do trabalho de um app em React Native é feito na Thread JavaScript, então não passamos a maior parte do tempo nos comunicando com o núcleo nativo - apenas quando necessário (essa é uma das principais vantagens do RN frente a outros frameworks híbridos).
Erros comuns que podem levar a vazamentos de memória

Embora o Javascript faça uso de um Garbage Collector para gerenciar a memória, não estamos livres de problemas relacionados a vazamentos e coletas excessivas.
"The main cause for leaks in garbage collected languages are unwanted references."
No mundo React Native, cada escopo do módulo JS é anexado a um objeto raiz. Muitos módulos, incluindo os principais React Native, declaram variáveis que são mantidas no escopo principal (por exemplo, quando você define um objeto fora de uma classe ou função em seu módulo JS). Essas variáveis podem reter outros objetos e, portanto, evitar que sejam coletados como lixo. Quando isso acontece, temos o que é chamado de vazamento de memória.
Abaixo está alguns dos erros mais comuns em aplicativos React Native que podem levar a vazamentos de memória:
Ouvintes de eventos
class Composer extends Component {
state = { showAccessory: false }
componentDidMount() {
Keyboard.addListener('keyboardDidShow', () => this.setState({ showAccessory: true }));
Keyboard.addListener('keyboardDidHide', () => this.setState({ showAccessory: false }));
}
render() {
return (
<View>
<EditTextComponent />
{this.state.showAccessory && <AccessoryView />}
</View>
);
}
}
Embora o código acima use componentes de classes, ele servirá para ilustrar o problema que ainda persiste em componentes funcionais.
No exemplo, criamos dois ouvintes de eventos do teclado. Toda vez que o evento é acionado o estado do componente é alterado. O problema aqui é que, como nunca removemos esses ouvintes, eles ainda receberão eventos de teclado mesmo depois que o componente for desmontado. Ou seja, o objeto global Keyboard manterá as arrow functions vivas no escopo global. O problema aqui é que essas funções retêm outros objetos, como this — ou seja, a referência ao componente Composer — , que por sua vez faz referência a suas propriedades via this.props, seus filhos via this.props.children, os filhos dos filhos, etc. Esse simples erro pode levar a áreas muito grandes de memória deixadas retidas acidentalmente.
Uma solução para esse problema é não esquecer de remover os ouvintes quando o componente é desmontado:
class Composer extends Component {
state = { showAccessory: false };
componentDidMount() {
this.keyboardDidShowListener = Keyboard.addListener('keyboardDidShow', () =>
this.setState({ showAccessory: true })
);
this.keyboardDidHideListener = Keyboard.addListener('keyboardDidHide', () =>
this.setState({ showAccessory: false })
);
}
componentWillUnmount() {
this.keyboardDidShowListener.remove();
this.keyboardDidHideListener.remove();
}
render() {
return (
<View>
<EditTextComponent />
{this.state.showAccessory && <AccessoryView />}
</View>
);
}
}}
Closures e Escopos
Em linguagens de programação funcional (como é o caso do Javascript) um encerramento (closure) é um registro que armazena uma função junto com o seu ambiente léxico, isso permite que os objetos de função tenham acesso a variáveis definidas em seu escopo externo, mesmo quando esse escopo é concluído. Variáveis locais que são capturadas/referenciadas por um encerramento são coletadas como lixo uma vez que a função em que são definidas e as funções que a retêm tenham terminado.
Vazamentos em closures são mais difíceis de serem percebidos, e isso se deve a uma idiossincrasia do próprio paradigma funcional: o compartilhamento de um escopo pai entre escopos filhos.
var theThing = null;
var replaceThing = function() {
var originalThing = theThing;
var unused = function() {
if (originalThing)
console.log("hi");
};
theThing = {
longStr: new Array(1000000).join('*'),
someMethod: function() {
console.log(someMessage);
}
};
};
setInterval(replaceThing, 1000);
Repare que a função replaceThing é o escopo pai de duas closures: unused e someMothod . A princípio nada de mais, correto? Visto que, embora unused faça referência a originalThing , ela é coletada pelo GC quando a função replaceThing se encerra e em consequência originalThing também será coletado visto que não é mais retido por ninguém. Porém, esse pensamento é inevocadamente errado.
Ao analisarmos o desempenho da memória quando esse script é executado, temos o seguinte resultado:

O uso da memória aumenta a cada segundo, ou seja, aparentemente o GC não está coletando a nossa variável como deveria. Mas como isso é possível? originalThing só é referenciado no escopo principal e na função unused (que nunca é usado e consequentemente é limpo pelo GC). A resposta está no compartilhamento de escopo comentado logo acima.
Em um determinado escopo pai, a VM Javascript só criará um ambiente léxico que será compartilhado entre todos as closures (funções) criados nesse escopo pai. Portanto, assim que uma variável é usada por qualquer closure, ela termina no ambiente léxico compartilhado por todas as closures naquele escopo. Assim, someMethod acaba obtendo uma referência indireta a originalThing. someMethod não é coletado pelo GC, pois ela é atribuída a variável theThing que pertence ao escopo global e por consequência impedirá que originalThing seja coletado, mantendo um objeto gigante na memória a cada iteração do setInterval.
Uma solução para esse problema é atribuir um valor nulo ao final do escopo pai:
var theThing = null;
var replaceThing = function() {
var originalThing = theThing;
// Define um encerramento que faz referência a originalThing, mas nunca
// é realmente chamado. Mas, como esse encerramento existe,
// originalThing estará no ambiente léxico para todos
// os encerramentos definidos em replaceThing, em vez de ser otimizado
// a partir dele. Se você remover esta função, não haverá vazamento.
var unused = function() {
if (originalThing)
console.log("hi");
};
theThing = {
longStr: new Array(1000000).join('*'),
// Embora originalThing seja teoricamente acessível por esta
// função, obviamente não a usa. Mas porque
// originalThing faz parte do ambiente léxico, someMethod
// manterá uma referência a originalThing e, portanto, mesmo que
// estejamos substituindo theThing por algo que não tem
// uma maneira eficaz de fazer referência ao valor antigo de theThing, o valor antigo
// nunca será limpo!
someMethod: função() {}
};
originalThing = null
};
setInterval(replaceThing, 1000);
Criação de objetos em loops
Embora esse problema não seja um vazamento de memória, ele pode causar quedas no desempenho do aplicativo.
Criar objetos dentro de um loop faz com que muita memória seja alocada. Esse fato pode causar uma sobrecarga no trabalho do GC, fazendo com que o sistema realize a coleta com mais frequência e por períodos mais longos de tempo. O resultado é um aplicativo lento, com sucessivos travamentos e até encerramentos inesperados (out of memory).
Identificando vazamentos de memória
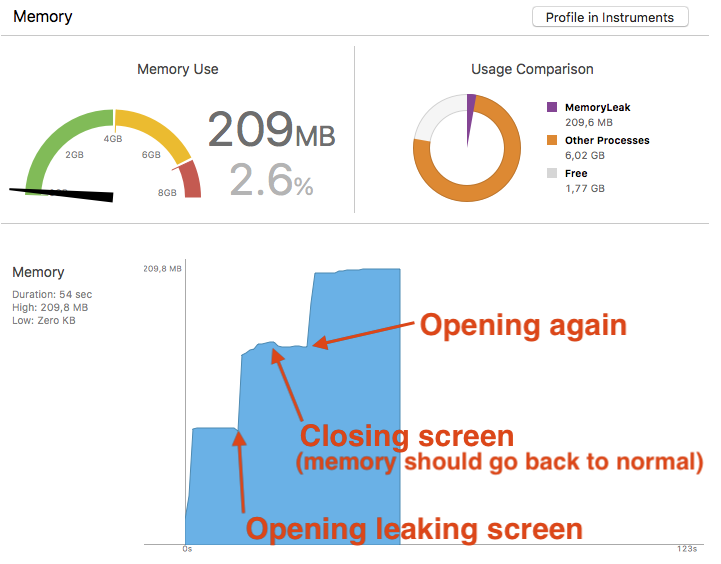
Podemos indentificar possíveis vazamentos de memória analisando o fluxo de trabalho do aplicativo. Para isso, podemos usar o próprio Android Studio ou VSCode como ferramenta de análise, visto que ambos possuem um mecanismo para isso: Android Studio Profiler e VSCode Debug Navigator.
Ao abrir o gráfico de análise de memória, navegue para alguma página em seu aplicativo e depois retorne a página anterior. Se você ver um aumento no gráfico que não diminuiu após você voltar a tela anterior, pode ser que haja um vazamento de memória.
Conclusão
Vimos como é extremamente importante entender os fundamentos da computação para escrever bons programas. Conseguimos perceber que os frameworks e as linguagens não possuem a palavra final e não devem ser endeusados, pois são apenas ferramentas que se não forem bem utilizadas, não resolverão nossos problemas.
Espero que esse artigo tenha te ajudado de alguma forma, e se você chegou até aqui com um pensamento mais maduro em relação a programação, a minha meta foi cumprida :)
Não esquece de curtir e compartilhar.
Nos vemos em breve!