Qual modelo de IA usar para coding em 2026: benchmark real cruzado com preço do Copilot
Um guia baseado no DeepSWE (Mai/2026) e na nova tabela de preços do GitHub Copilot (Jun/2026)
Cruzei os dados do DeepSWE com os preços do GitHub Copilot. O resultado muda o que se assume sobre Claude Opus
Em junho de 2026, o GitHub Copilot migrou a cobrança de “requests por mês” para tokens consumidos. De repente, a escolha do modelo virou uma decisão, além de técnica, financeira real.
Então fiz o que qualquer engenheiro pragmático faria: cruzei os dados de performance do DeepSWE — o benchmark de coding mais rigoroso disponível hoje — com a nova tabela de preços do Copilot. Para o cálculo de custo, usei os tokens de output do DeepSWE e estimei os tokens de input de cada sessão agêntica, aplicando os preços exatos do Copilot para cada provedor — incluindo o custo de cache write da Anthropic, ausente nos custos de API reportados pelo benchmark.
TL;DR: Cinco conclusões
Se você tem dois minutos, estas são as descobertas que este artigo detalha com dados:
- 01 · Melhor custo-benefício no Copilot. GPT-5.5
[medium]— **4,88 por sucesso.** Não é o modelo mais caro nem o de maior score. É o que resolve mais tarefas por real gasto — 48% de taxa de sucesso a 2,34 por tentativa. - 02 · Modo > modelo. O esforço de raciocínio é a maior alavanca de custo. Para o mesmo modelo, trocar de
[max]para[medium]pode reduzir o custo por sucesso em até 4×. Configurar o modo certo vale mais do que escolher o modelo certo. - 03 · Pior custo-benefício disponível Claude Opus 4.7
[max]— $36,15 por sucesso. 7× mais caro que GPT-5.5[medium]por tarefa bem-sucedida. Score apenas 6 pontos percentuais maior. O modo[max]da Anthropic cobra caro por thinking tokens invisíveis. - 04 · O paradoxo do preço por token. GPT-5.5 paga mais por token, mas usa muito menos tokens. Output a 30/M vs 25/M do Opus 4.8, mas o GPT-5.5 usa menos da metade dos tokens por tarefa. A eficiência de tokens vence o preço por token.
- 05 · Gemini não é a alternativa que parece. Gemini 3.5 Flash: $26,50/sucesso apesar de barato. O modelo gera 4x mais tokens por tarefa . O custo é alto mesmo com preço por token mais baixo.
Abaixo detalhando como encontramos estes dados.
Por que o SWE-bench não é suficiente
O SWE-bench domina os leaderboards. O problema é que ele foi construído a partir de código já existente, o que cria um risco de contaminação: os modelos podem ter visto as soluções durante o treino.
O DeepSWE resolve isso de um jeito elegante: todas as tasks são inéditas, escritas do zero por engenheiros humanos, e as soluções nunca são mergeadas de volta nos repositórios públicos. As tasks refletem trabalho real de engenharia: prompt médio de 2.158 caracteres, mas a solução de referência exige em média 668 linhas de código em 7 arquivos diferentes.
O resultado é que o DeepSWE separa os modelos com gaps muito maiores do que o SWE-bench. Por exemplo, Claude Sonnet 4.6 de 54% no SWE-bench para 32% no DeepSWE. Isso não é ruído, é o benchmark mostrando o que acontece quando a task é difícil de verdade.
Custo por tarefa bemsucedida no Copilot:
Com a cobrança por token, a pergunta certa não é “qual modelo é melhor?” mas “qual modelo entrega mais resultado por real gasto no Copilot?”
Press enter or click to view image in full size
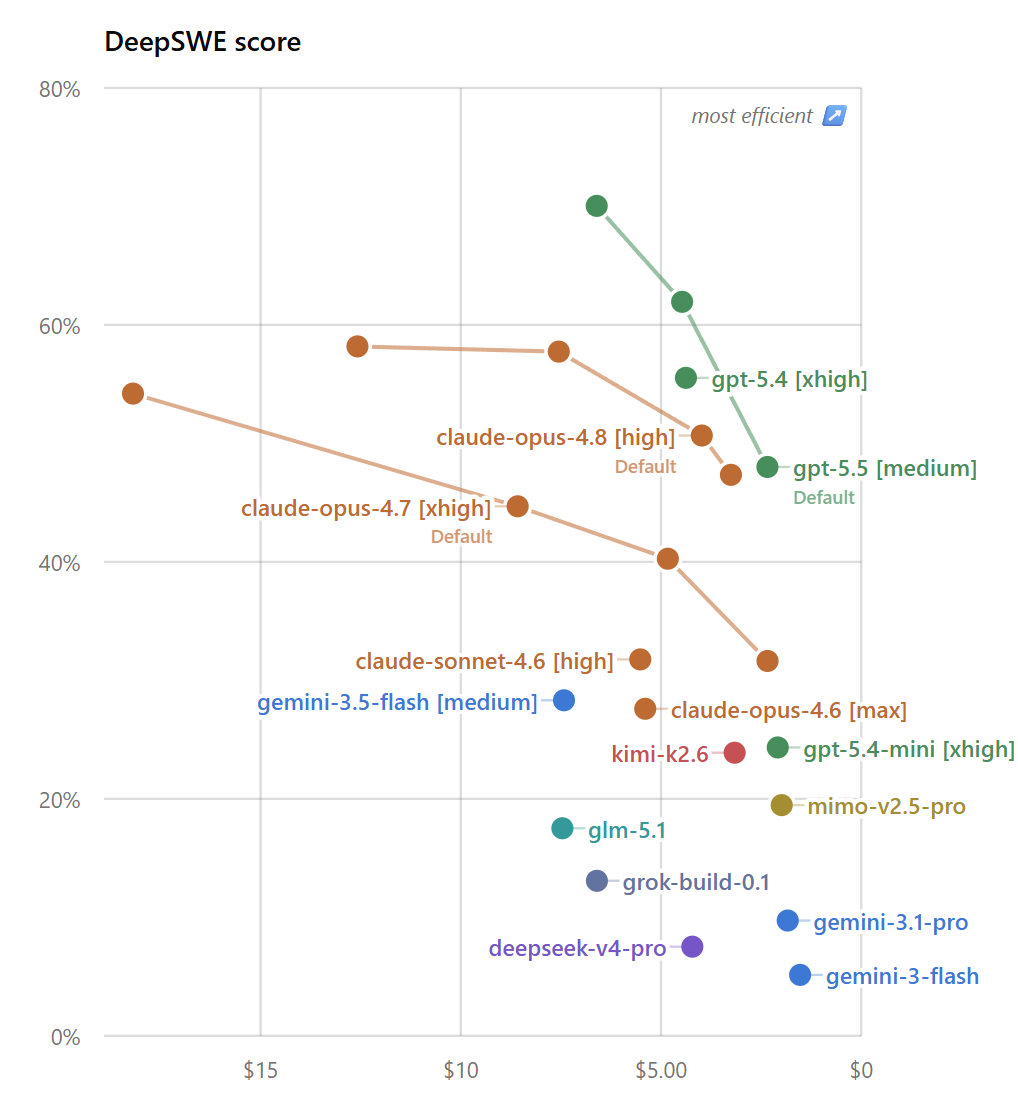
Custo por sucesso = custo médio por tentativa ÷ taxa de sucesso
Para o cálculo de custo no Copilot: usei os tokens de output reportados pelo DeepSWE, estimei os tokens de input com base nos custos de API, e apliquei a tabela de preços do Copilot para cada provedor.
Para modelos OpenAI e Google, os preços de API são idênticos aos do Copilot, verificado matematicamente. contudo Para Anthropic, o Copilot cobra adicionalmente pelo cache write. um aumento de 10 a 20% nos modelos Anthropic.
O modo importa mais do que o modelo
Esse é o dado mais importante da análise e o que mais vai mudar como você configura seu time.
Press enter or click to view image in full size
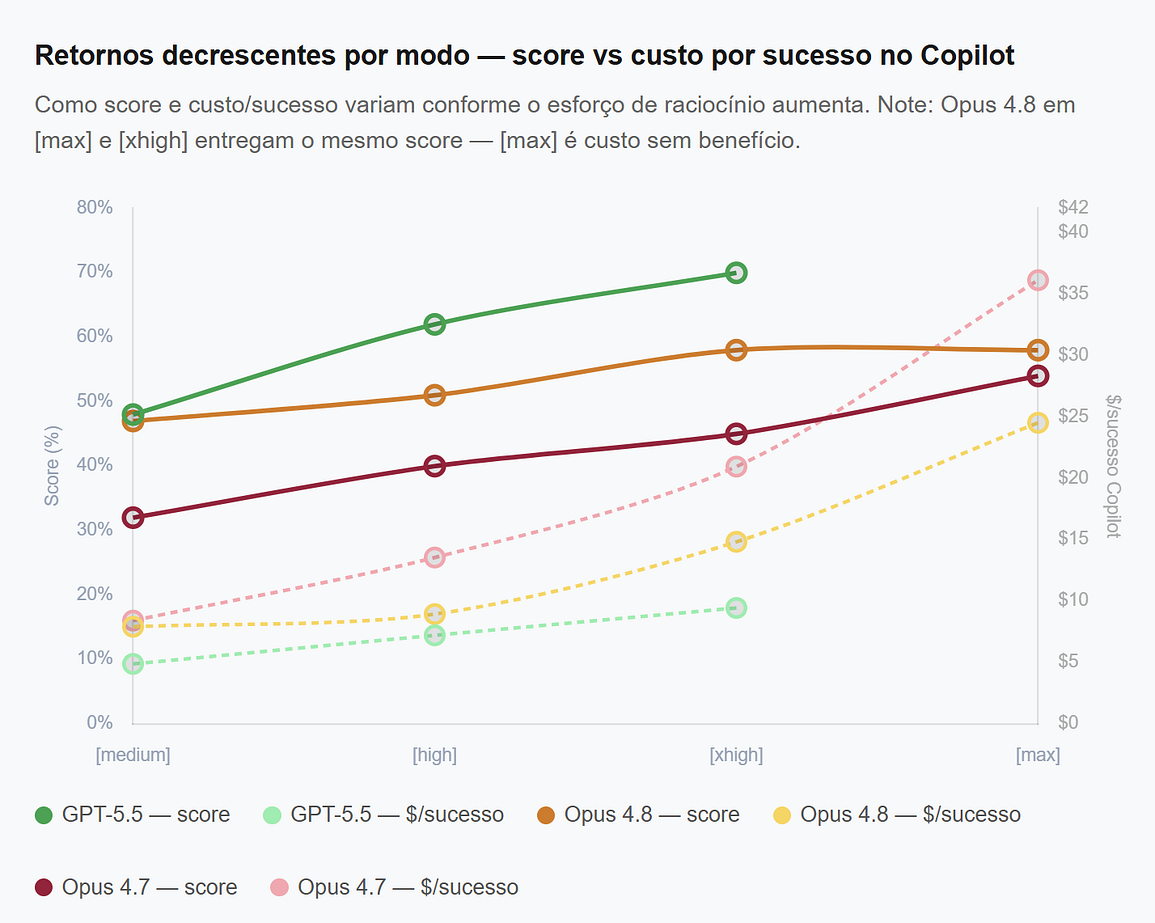
Para o mesmo modelo, a diferença de custo/sucesso entre modos pode ser de 4 a 7×. O exemplo mais dramático é o Claude Opus 4.7 no Copilot:
[medium]: 32% de score a 2,69/trial → **8,41 por sucesso no Copilot**[high]: 40% a 5,42 → 13,55 por sucesso[xhigh]: 45% a 9,43 → 20,96 por sucesso[max]: 54% a 19,52 → **36,15 por sucesso no Copilot**
Do [medium] ao [max], o score sobe 22 pontos percentuais. O custo por sucesso no Copilot sobe 4,3×.
O caso mais revelador é o Claude Opus 4.8: em [max] e [xhigh] o modelo entrega o mesmo score (58%), mas o [max] custa 14,23 contra 8,60 do [xhigh] no Copilot. Zero benefício adicional por 65% a mais de custo.
Resumindo: você pode rodar Claude Opus 4.7 em modo máximo uma vez no Copilot, ou rodar GPT-5.5 em modo médio 8 vezes pelo mesmo preço — com score muito próximo por tentativa e resultado agregado muito melhor.
O DeepSWE também documenta um comportamento recorrente do Claude Opus: ele tende a esquecer sub-requisitos em prompts com partes paralelas
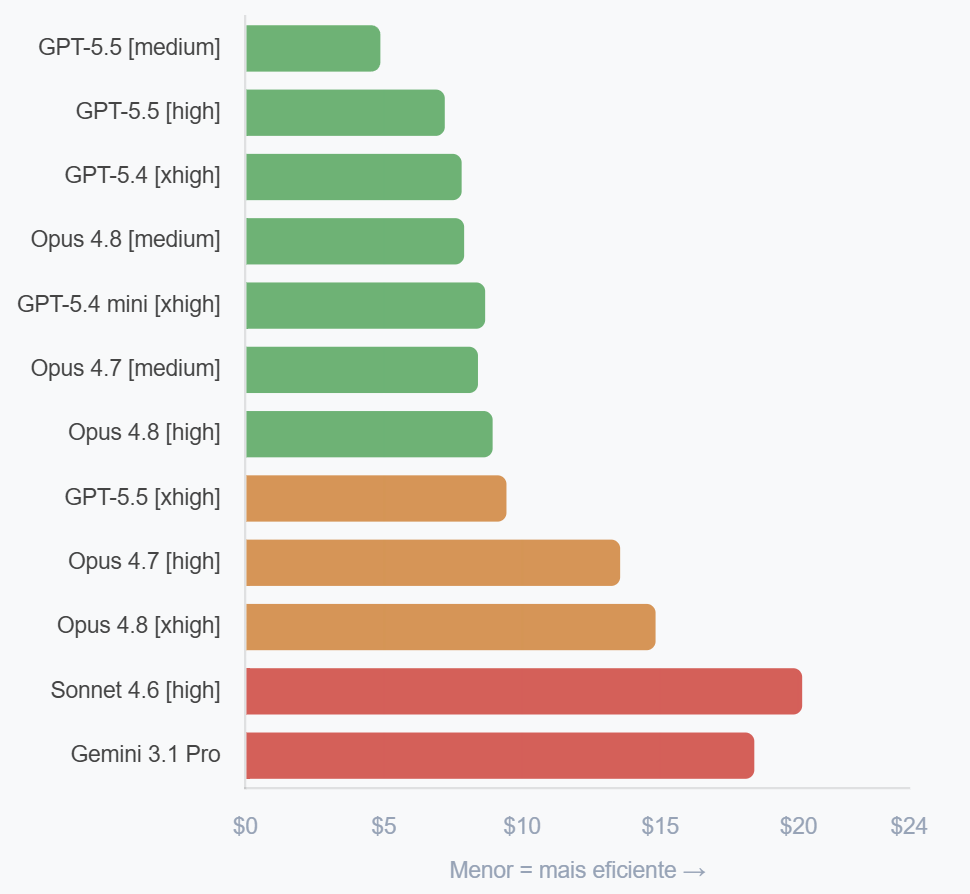
Ranking de eficiência. custo por tarefa bem-sucedida no Copilot
Top 12 combinações disponíveis no Copilot, com preços reais. Menor = mais eficiente.
Press enter or click to view image in full size
Por que o GPT-5.5 sai mais barato apesar de custar mais por token
Uma contradição aparente nos dados merece atenção direta: o GPT-5.5 cobra **30/M de output** — 20% mais caro que os 25/M do Claude Opus 4.8. Como termina sendo mais barato por tarefa?
A resposta está na eficiência de tokens: quantos tokens o modelo precisa para resolver uma tarefa, independente do preço unitário. O GPT-5.5 termina a mesma tarefa usando menos da metade dos tokens do Opus 4.8.
Press enter or click to view image in full size
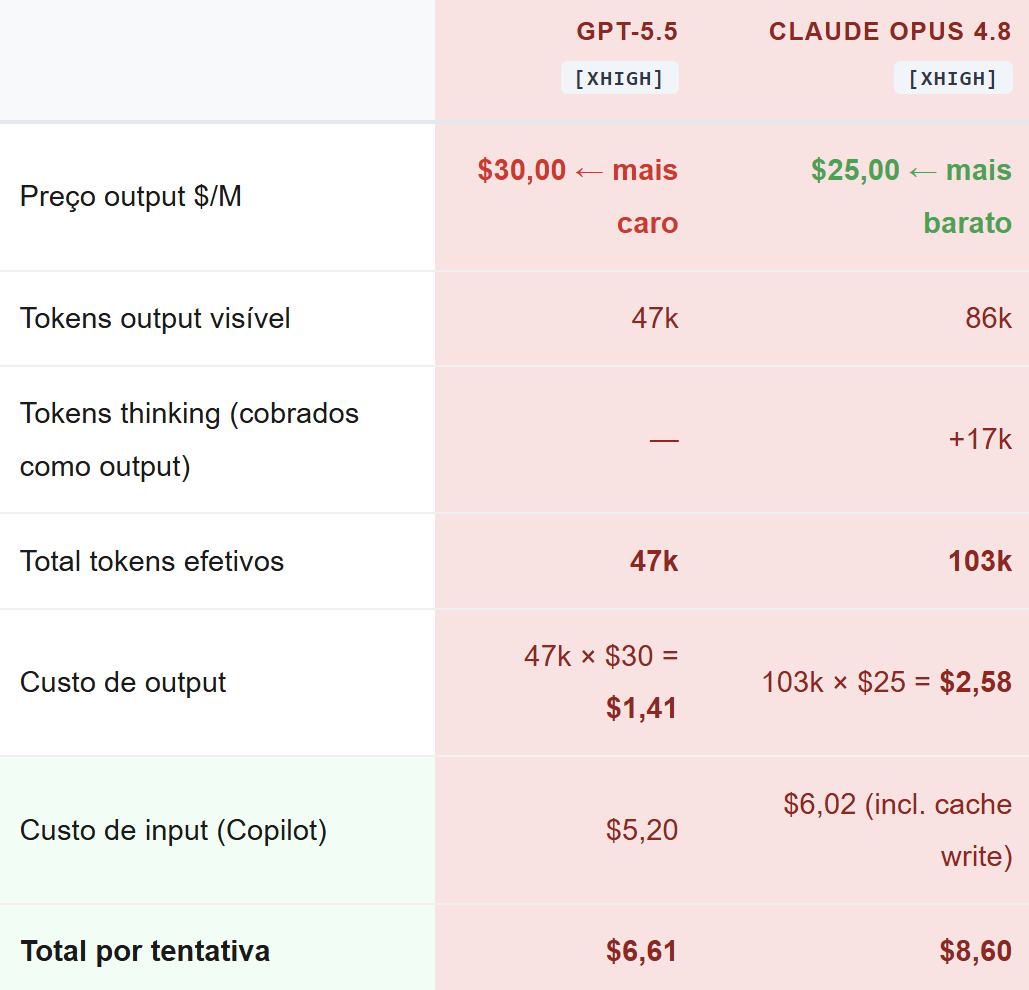
- Cache write (6,25/M): o Copilot cobra para gravar o contexto no cache. Em \[xhigh\], isso adiciona 3,73 por sessão.
- Thinking tokens ocultos: o raciocínio interno do Claude é cobrado como output, mas não aparece no contador de tokens da resposta. Em [max], somam centenas de milhares de tokens adicionais por sessão.
A lição: preço por token e custo por tarefa são métricas diferentes. Um modelo pode cobrar mais por token e ainda assim ser mais barato por resultado — se for mais eficiente no uso de tokens. É isso que o DeepSWE mede que benchmarks simples não capturam.
. . .
Metodologia: Tokens de output e custos de API do DeepSWE (Datacurve, Mai/2026). Tokens de input estimados por: _input = (custo_api − out×preço_out) / preço_in_. Custos Copilot calculados com preços da tabela oficial do GitHub Copilot (Jun/2026), incluindo custo de cache write Anthropic (taxa efetiva de input: 6,05/M para Opus, 3,63/M para Sonnet, assumindo 60% de cache write e read por sessão agêntica). OpenAI e Google: verificados matematicamente — preço API = preço Copilot.