Pitch: Por que telemetria local é subestimada (e como ela pode salvar seu debug)
Sabe aquele bug que só aparece em produção? Aquele gargalo de performance que você descobriu tarde demais? Pois é. A maioria dos devs só pensa em telemetria quando o sistema já está no ar (quando pensa kkk), mas telemetria local é uma das práticas mais subestimadas do desenvolvimento moderno
O problema que ninguém fala
Durante o desenvolvimento, a gente costuma debugar de forma rudimentar: um console.log aqui, um breakpoint ali, talvez uns prints estratégicos. Funciona? Sim. É eficiente? Nem tanto.
O grande problema é que esse tipo de debug é reativo, limitado e não reproduzível. Você só vê o que está acontecendo agora, naquele exato momento. Perdeu o contexto de uma requisição anterior? Tough luck. Quer entender o fluxo completo de uma operação assíncrona? Boa sorte rastreando cada callback. E quando você fecha o terminal? Todo o histórico de debug desaparece.
Telemetria local: o debug que você deveria estar fazendo
Telemetria não é só para produção. Quando você instrumenta seu código durante o desenvolvimento, você ganha:
1. Visibilidade completa do fluxo de execução
- Traces mostram todo o caminho de uma requisição, do início ao fim
- Você vê exatamente onde o tempo está sendo gasto
- Operações assíncronas ficam óbvias, não misteriosas
2. Detecção precoce de gargalos
- Aquela query que demora 2 segundos? Você vai ver antes de fazer deploy
- Loops ineficientes aparecem claramente nos traces
- N+1 queries ficam escancaradas
3. Contexto completo para debugging
- Logs correlacionados com traces e métricas
- Você sabe não só o que falhou, mas por quê
- O estado completo da aplicação está disponível
- O histórico persiste - você pode analisar execuções passadas a qualquer momento
4. Iteração mais rápida
- Não precisa mais ficar adicionando e removendo logs
- O histórico fica salvo, você pode analisar depois
- Comparar diferentes execuções fica trivial
O argumento contra "mas isso é complexo demais"
Durante anos, telemetria local era realmente complexa. Você precisava:
- Subir um Docker Compose com Jaeger ou Zipkin
- Configurar collectors, exporters, backends
- Lidar com múltiplos containers só pra debugar
- Esperar tudo isso inicializar antes de começar a trabalhar
E convenhamos, ninguém quer fazer isso só pra debugar uma feature simples.
A solução: local-first observability
Foi pensando nisso que criei o Faze. A ideia é simples: telemetria local deve ser tão fácil quanto rodar bun run start.
Como funciona:
- Binário único, zero dependências externas
- Suporta OTLP (OpenTelemetry Protocol) out of the box
- Interface web embarcada para visualizar os dados
- Armazenamento em SQLite (por projeto)
- Não precisa de Docker, não precisa de nada
Você literalmente roda:
faze serve
E pronto. Seu collector OTLP está rodando, a UI está disponível em localhost:7070 (ou na porta que preferir), e você pode começar a instrumentar seu código.
Quando NÃO usar o Faze
Se você já tem um setup de observabilidade complexo funcionando bem no desenvolvimento (tipo um stack completo com Grafana, Prometheus, Jaeger configurado), provavelmente não precisa disso. O Faze é ideal para quem quer começar com telemetria local sem fricção, ou para times que acham o setup tradicional pesado demais para desenvolvimento.
Um exemplo prático
Imagina que você está desenvolvendo uma API. Com telemetria local:
- Você instrumenta suas funções principais com OpenTelemetry
- O Faze coleta automaticamente todos os traces, logs e métricas
- Na UI, você vê o flamegraph completo de cada requisição
- Percebe que uma função específica está demorando 80% do tempo total
- Otimiza a função antes de fazer merge no PR
Sem telemetria, você provavelmente só descobriria isso em code review (se tiver sorte) ou em produção (mais provável).
E o overhead?
A instrumentação OpenTelemetry tem um overhead mínimo - geralmente menos de 5% em latência para aplicações típicas. Em desenvolvimento, isso é irrelevante. Em produção, você pode usar sampling (coletar apenas uma porcentagem dos traces) para reduzir ainda mais o impacto. O importante é que a instrumentação já está lá quando você precisa.
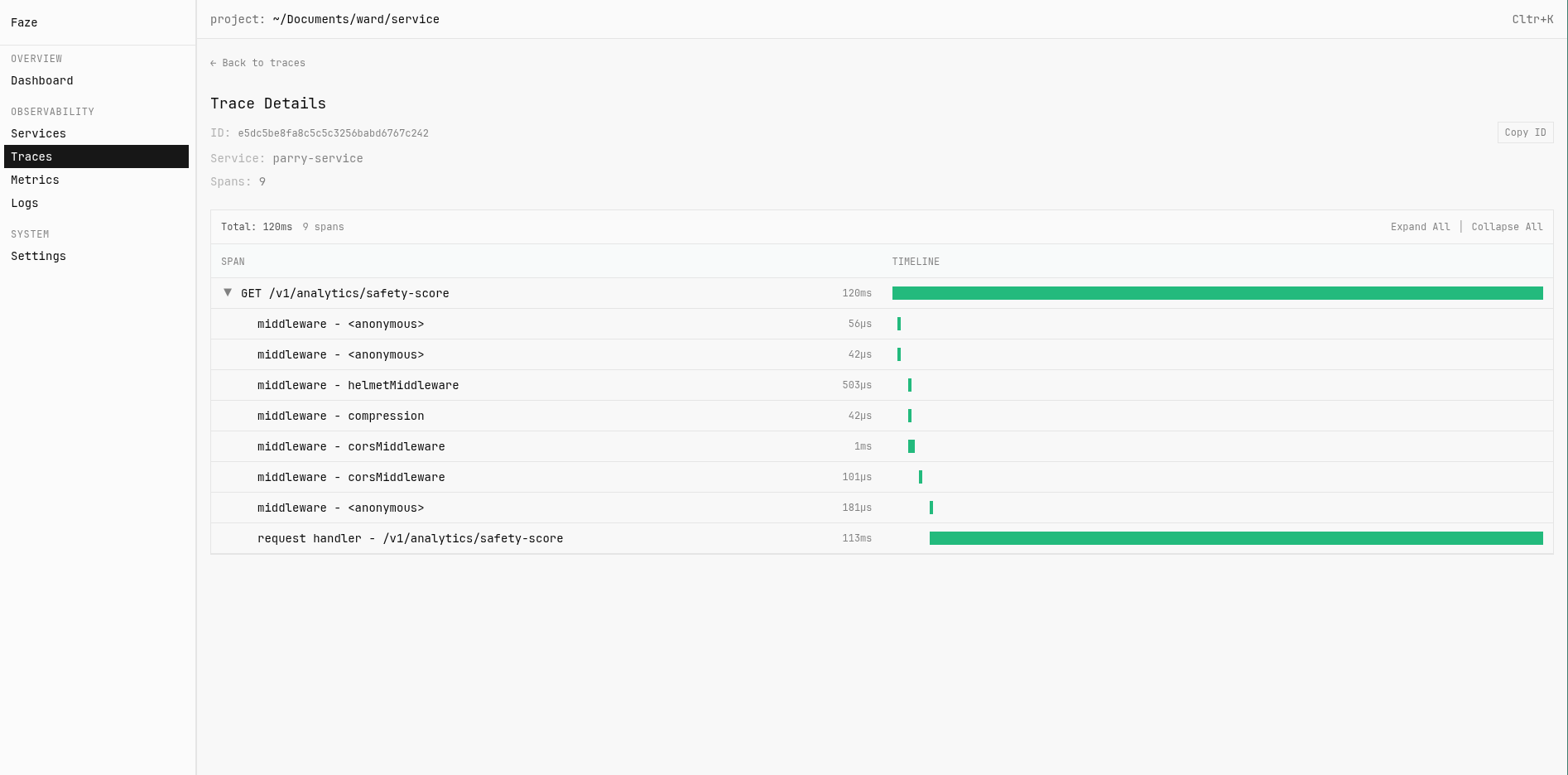
Telemetria e o ciclo de desenvolvimento
A telemetria local muda fundamentalmente como você desenvolve:
Antes:
- Escreve código
- Testa manualmente
- Parece funcionar
- Faz commit
- Descobre problema em produção
- Adiciona logs
- Redeploy
- Repete
Com telemetria local:
- Escreve código com instrumentação
- Roda localmente
- Analisa traces e métricas
- Identifica e corrige problemas antes do commit
- Faz commit com confiança
- Produção roda suave
Observabilidade é uma prática, não uma ferramenta
A verdade é que observabilidade não começa em produção. Ela começa no seu ambiente de desenvolvimento. Quando você instrumenta seu código desde o início:
- Você entende melhor o que está construindo
- Você detecta problemas mais cedo
- Você itera mais rápido em otimizações
- Você ganha confiança no código que escreve
E o melhor: quando chega em produção, a instrumentação já está lá. Você não precisa adicionar logs depois que o problema aparece.
Por onde começar
Se você nunca usou telemetria local:
- Instale uma ferramenta simples (como o Faze, mas pode ser qualquer collector OTLP)
- Instrumente uma função do seu projeto com OpenTelemetry
- Execute e observe o que acontece
- Repita para outras partes críticas
Você vai se surpreender com o que descobre sobre o próprio code.
Por fim
Telemetria local não é overhead. É investimento.
O tempo que você gasta instrumentando código é recuperado toda vez que você:
- Encontra um bug antes de fazer deploy
- Otimiza uma função sem precisar de profiler
- Entende um comportamento complexo sem debug manual
- Resolve um problema em minutos ao invés de horas
Se você ainda não está usando telemetria durante o desenvolvimento, está perdendo uma das melhores ferramentas de produtividade disponíveis.