Encontrando Os Vértices De Um Documento Em Uma Foto Com Python e OpenCV
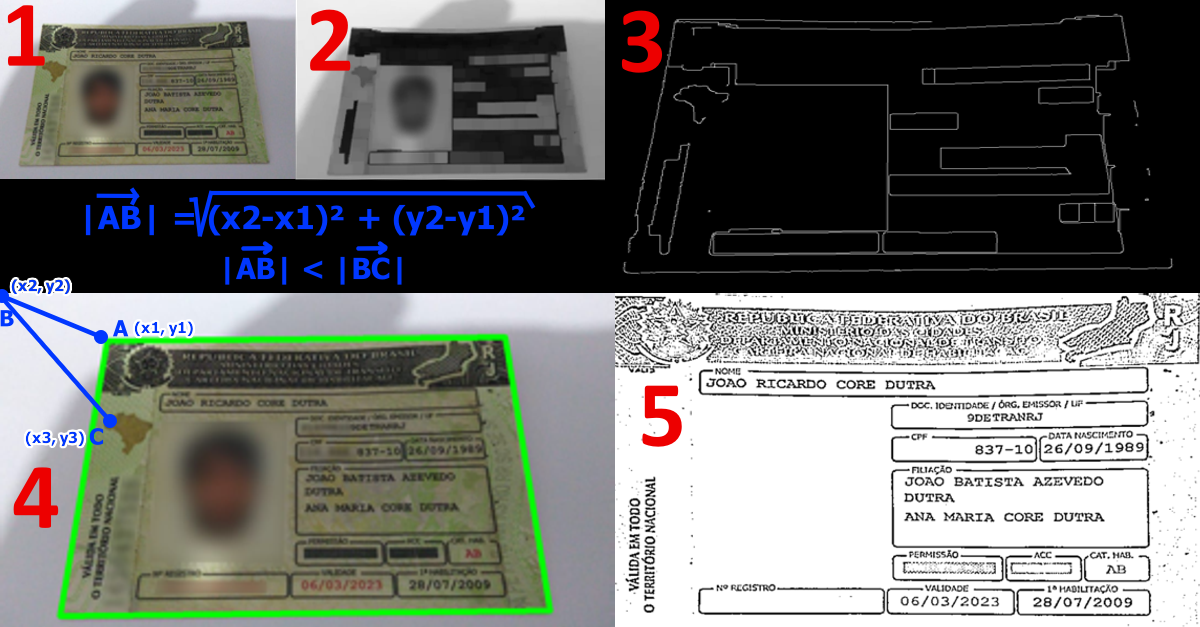
Olá Pessoal do TabNews! Nessa semana um problema vinha martelando na minha mente rsrs. Eu estava com a necessidade de fazer uma técnica chamada OCR (Reconhecimento ótico de caracteres, ou seja, extrair textos de imagens) em documentos como CNH, RG, CRLV etc etc. Porém a biblioteca para fazer o OCR, a tesseract, não estava se comportando muito bem com os documentos. Então, mexendo aqui e ali, percebi que essa biblioteca não se dava muito bem com imagens muito coloridas e cheia de padrões. Portanto resolvi fazer um tratamento prévio na imagem. A primeira coisa que tentei foi colocar em tons de cinza, mas sem muito sucesso, ainda eram muitas informações para a biblioteca interpretar. Sendo assim, resolvi buscar algum material com sugestões de como tratar a imagem e encontrei um que sugeria uma solução semelhante a esses scanners de celular. Encontrei o artigo Building document scanner with opencv and python e fui seguindo. Se vocês abrirem esse artigo, vão perceber que ele especifica 3 passos que são correspondentes às figuras 3, 4 e 5. Entretanto, ao implementar a sequência de códigos e passos sugeridos, eu percebi ainda que as imagens que eu estava inserindo ainda estavam cheias de informações para a biblioteca OpenCV interpretar e manipular de forma a obter um resultado minimamente aceitável para o meu objetivo.
Só para adiantar, o maior desafio desse tratamento foi achar de alguma maneira os 4 pontos referentes aos 4 vértices na imagem, correspondendo aos vértices do documento em questão. Ao introduzir o passo 2, o resultado foi significativamente melhor, a OpenCV conseguiu encontrar de maneira muito mais substancial as arestas presentes na imagem do documento, porém ainda havia um problema, como posso reconhecer os vértices do documento nesta imagem? São tantos pontos encontrados correspondentes à diversas arestas na imagem do documento... Se vocês observarem, o artigo Building document scanner with opencv and python e muitos outros que tratam de maneira semelhante do mesmo tema, sempre utilizam imagens de documentos sem muitos desenho geométricos, constando predominantemente textos nos documentos de exemplo, realidade diferente de CNHs, RGs e CRLVs.
Partindo do fato que eu já tinha os pontos na imagem que estavam marcando as arestas encontradas (passo 3), logo me veio uma ideia para alcançar o meu objetivo de encontrar os 4 vértices do documento na foto e que poderia ser resolvida com matemática de ensino médio (equação mostrada na imagem). Percebi que dentre os pontos que eu já tinha encontrado na imagem, os pontos que representam os 4 vértices do documento da foto coincidiriam, com um certo erro, aos mais próximos de cada canto da imagem. Mas como encontrar esses pontos? Foi bem simples a implementação. Sabendo que o módulo do vetor correspondente à um certo ponto no canto da imagem e um ponto aleatório encontrado no documento, corresponde à distância entre esses dois pontos. Sendo assim, foi só encontrar o ponto no documento que possuía a menor distância para cada extremidade da imagem, logo seriam os pontos correspondentes aos vértices do documento na foto. Dessa forma, testei a distância de todos os pontos em cima do documento (presentes no passo 3) para cada canto da imagem, pegando o ponto de menor distância para cada caso, o que resultou na marcação apresentada no passo 4. A partir daí, foi só seguir o artigo para fazer a transformação da imagem.
Dessa forma foi possível a partir de uma foto de um documento em uma perspectiva não muito reta, encontrar os vértices do documento na foto e ajustar a imagem (mostrada no passo 5), facilitando assim a realização do OCR.
Vejam algumas etapas do processamento das imagens:





Me sigam no linkedin e até breve pessoal!