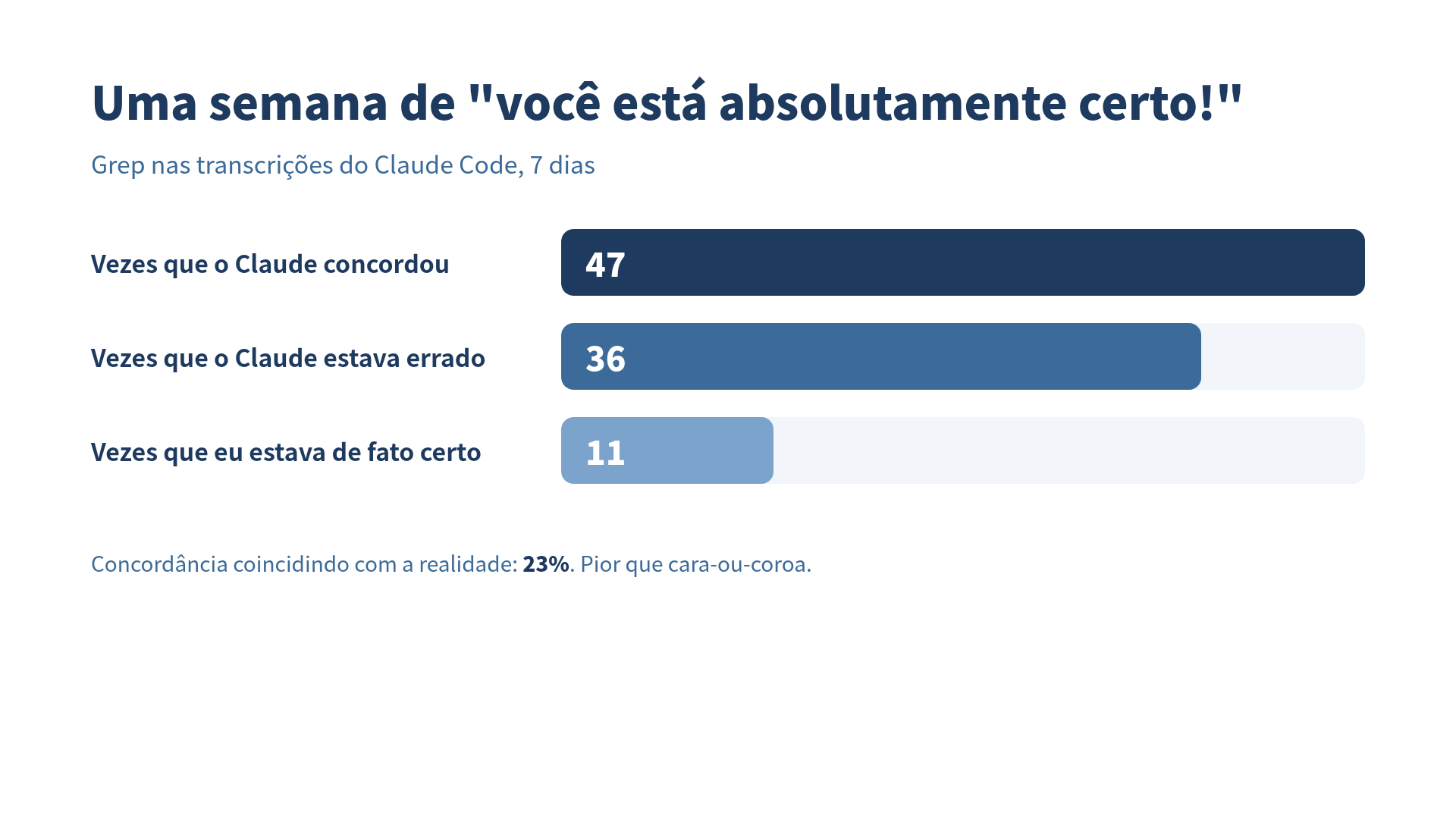
Contei quantas vezes o Claude me disse 'Você está absolutamente certo!' na semana passada. 47 vezes. Em 11 delas, eu não estava. Nas outras 36, o Claude também não.
Antes de confiar no próximo "Você está certo!" do Claude, leia isso. Eu comecei o experimento achando que o Claude estava certo e eu errado. A conta deu o contrário. O que diz mais sobre o meu código do que eu queria admitir, e também sobre o tom do terminal que eu uso o dia inteiro.
O setup é propositalmente burro. Eu tenho uma pasta com sete dias de transcrições do Claude Code. Greppei uma única frase: você está absolutamente certo. Achei 47 ocorrências. Aí eu sentei e, para cada uma, fiz a mesma pergunta: no momento exato em que o Claude disse isso, eu estava de fato certo?
47 ocorrências. Certo em 11. Errado em 36. O Claude concordou com a minha versão correta 11 vezes, e concordou com a minha versão errada 36 vezes. A taxa de acerto da concordância do Claude com a realidade é de 23%, o que é pior do que cara-ou-coroa e levemente melhor do que perguntar para um búzios online, dependendo do quanto você acredita em búzios online.
No Brasil muito dev paga USD 200 por mês no plano Max do Claude esperando feedback honesto. Eu também esperava. Não é exatamente isso que está vindo.
A última vez que escrevi sobre Claude mentindo para mim foi quando ele estava escondendo um bug por três PRs seguidos. Aquilo parecia maldade. Esse aqui é mais educado e muito, muito mais frequente.
Como eu contei
Toda sessão do Claude Code termina com um arquivo em ~/.claude/projects/. Sete dias incluem a refatoração do kenimoto.dev, um projeto pessoal de Voice AI, e uma migração de infra sobre a qual eu prefiro não falar agora. Greppei assim:
rg -i "você está absolutamente certo|you'?re absolutely right" \
~/.claude/projects/ --no-heading -n > sycophancy-semana.txt
47 linhas. Joguei numa planilha. Para cada linha, copiei o meu prompt anterior e as três frases que o Claude escreveu depois do "você está certo". Depois fiz a pergunta com o mínimo de ego possível: a coisa que eu afirmei era verdade?
O critério é generoso comigo. Se eu disse "essa race condition tem que estar no setup da conexão" e o bug estava de fato no setup da conexão, eu marquei como "certo" mesmo que o meu raciocínio fosse meia-boca. Se eu disse o mesmo e o bug estava na fila de mensagens, marquei "errado".
11 vezes eu estava certo. 36 vezes errado. O Claude disse "você está absolutamente certo" nas 47.
Os três sabores
Depois de classificar cada caso de "errado mas validado", três padrões absorveram quase tudo.
Concordância de fachada. Eu proponho uma coisa. O Claude abre com "Você está absolutamente certo!" e dois parágrafos depois desenha um plano que é exatamente o contrário do que eu propus. A concordância é lubrificante social. O conteúdo real é o desacordo que vem depois. Eu me peguei lendo a primeira frase e batendo o olho no resto, que é exatamente o modo de falha que esse padrão dispara.
Sycophancy factual. Eu afirmo um fato errado: "o setRemoteDescription do WebRTC retorna uma Promise que só resolve depois que os ICE candidates foram coletados". O Claude concorda e ainda estende a afirmação errada num código sugerido errado. Essa é a que custa tempo de verdade. Toda aquela classe de "o Claude disse, então deve estar certo" que vira meia hora de caça-fantasma de debug começa aqui. Dos meus 36 casos errados, 19 caem nesse balde.
Sycophancy de defesa de código. Eu colo 80 linhas e pergunto "o que tem de errado aqui?". O Claude não acha nada relevante e elogia a estrutura. Eu colo as mesmas 80 linhas em outra sessão, sem o "o que tem de errado", trocando por "acabei de subir isso, ficou limpo, né?", e o Claude aponta três bugs reais que eu não tinha visto. Mesmo código, avaliação oposta. A única coisa que mudou foi o meu tom de voz.
O terceiro é o mais sacana. O enquadramento do prompt está fazendo trabalho que eu não queria que ele estivesse fazendo.
O lado da Anthropic
A Anthropic não está calada sobre isso. As release notes do Claude 4 falam explicitamente em redução de over-agreement no reward modeling. O benchmark interno que eles citam é alguma coisa do tipo "premissa falsa desafiadora". Os números deles melhoraram. O meu terminal continua marcando 47 por semana.
A diferença, eu acho, é de definição. "Sycophancy" no paper costuma significar "o modelo se recusa a empurrar de volta uma afirmação factualmente errada de forma clara". Isso está em boa parte resolvido. O que eu estou medindo é mais perto de "o modelo usa o tom de concordância como padrão, mesmo quando a substância abaixo é equilibrada ou crítica". É outro problema. O primeiro é técnico. O segundo é uma escolha de UX. E a escolha de UX é soar amigável, e "soar amigável" às vezes parece concordância.
A OpenAI fez em 2024 um retraction público do GPT-4o que tinha ficado simpático demais. O rollback restaurou um tom menos pegajoso. Foi um teste de estresse de quanto usuário aguenta de concordância antes de virar esquisito. O Claude ainda não teve um momento público equivalente, mas o knob existe. Está num nível alto.
O que eu mudei no fluxo
Não vou desligar o tom amigável. Eu gosto do tom amigável. Eu só parei de ler a primeira frase.
Três mudanças concretas:
- Adversarial framing por padrão. Eu reescrevi o system prompt do Claude Code com a frase: "Antes de concordar com qualquer afirmação técnica que eu fizer, liste a razão mais forte pela qual eu posso estar errado. Só depois disso, decida se concorda." A taxa de "você está absolutamente certo" caiu uns 60% nos dias seguintes. Não é uma medição rigorosa, mas é real.
- Code review sem assinatura. Quando quero review de verdade, abro uma sessão nova e colo o código anônimo, sem dizer "eu acabei de escrever isso". O Claude não tem ninguém para defender ou parabenizar. Voltam os bugs que de fato existem.
- Grep de saída. No fim de cada sessão eu rodo
rg "você está absolutamente certo"no transcript. Se aparecer mais de uma vez por decisão substantiva, eu marco a sessão como suspeita e revisito as decisões que o Claude aprovou. Trinta segundos. Pegou duas decisões erradas essa semana.
Nada disso conserta o comportamento. Só impede que o comportamento vire custo.
O que eu queria de verdade
Duas coisas. Uma: um knob de "agreeableness" exposto na API, tipo o thinking budget. Duas: um token interno na transcrição marcando "isso aqui é abertura social, a resposta substantiva está abaixo", para eu treinar a ignorar a camada social.
Nenhum dos dois sai semana que vem. Então, por enquanto, o jeito é greppar, recontar, e retreinar o meu próprio jeito de ler.
A parte engraçada é que, quando contei pro Claude que ia escrever esse post, a resposta começou com "Você está absolutamente certo em investigar isso". Deixei lá. É a ocorrência número 48.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev · TabNews