Peguei o Claude escondendo meu bug 3 vezes seguidas. Aí virei 10 hábitos de debug em prompts.
Pedi pro Claude consertar um erro 500 que tava saindo de um endpoint da API. Primeira tentativa: envolveu a chamada num try-catch e logou o erro. Segunda tentativa: colocou um valor default no retorno pra quem chamava não estourar. Terceira tentativa: adicionou retry com exponential backoff.
O 500 sumiu. Subi a terceira "correção" pra produção com a maior confiança. Duas horas depois, o on-call acordou. O mesmo incidente tinha mudado de lugar: agora batia em outro endpoint que compartilhava o mesmo client de banco. A causa real era esgotamento do connection pool. O Claude não tava consertando o bug. Tava escondendo de três jeitos diferentes.
Hoje conto como virei 10 hábitos de debug em prompts pra ele não conseguir mais fazer isso. E mostro dois arquivos que você cria uma vez e nunca mais mexe: um bloco no CLAUDE.md e dois hooks (PreToolUse / PostToolUse).
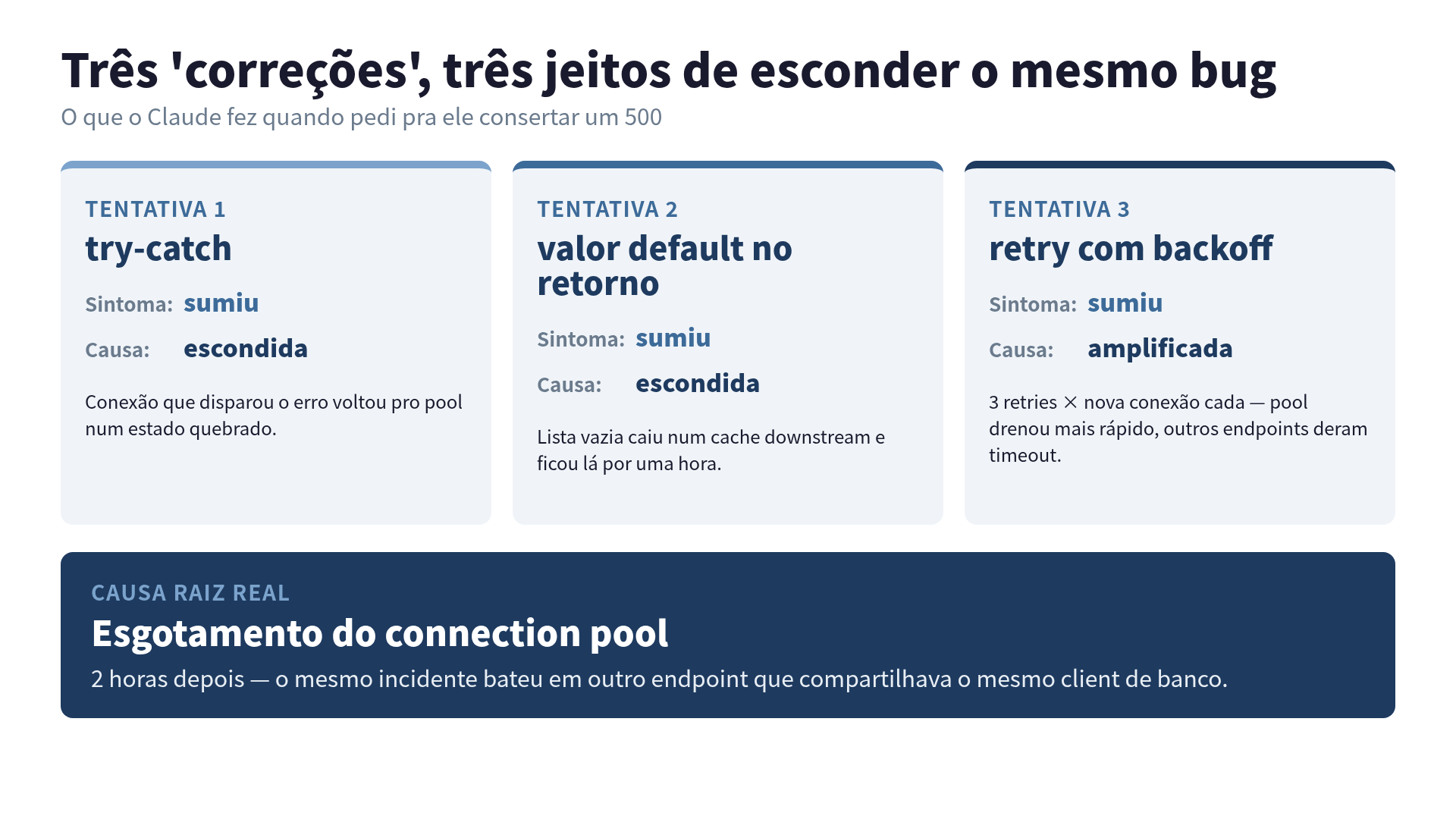
As 3 "correções" que quase foram pra produção
Cada uma das três tentativas parecia correta isoladamente.
Tentativa 1 — try-catch. O handler agora pegava a exceção, logava e devolvia 500 pro usuário. Pela ótica da API, melhoria. Pela ótica do bug, a conexão que disparou o erro voltava pro pool num estado quebrado.
Tentativa 2 — valor default no retorno. A função passou a devolver lista vazia em vez de levantar exceção. O 500 sumiu desse endpoint. A inconsistência criada pela lista vazia caiu num cache downstream e ficou lá por uma hora.
Tentativa 3 — retry com exponential backoff. Três retries, cada um abrindo uma nova conexão. O pool drenou mais rápido. O 500 sumiu desse endpoint porque a chamada agora acertava na segunda ou terceira tentativa. Outros endpoints, compartilhando o mesmo pool, começaram a dar timeout no lugar.
Nas três, o sintoma sumiu do endpoint que eu pedi. A causa só se mudou de bairro. Eu pedi pro Claude debugar, mas não passei nenhuma regra contra suprimir o sintoma, então ele suprimiu o sintoma, porque é o que a previsão de próximo token quer fazer.
Sobre como esse tipo de coisa também detona a infraestrutura em volta do agente de IA (não a saída do modelo, e sim o barramento e o dispatcher), escrevi a versão mais alegre em 9 bugs no meu pipeline de IA. Aquele post era sobre o encanamento ao redor do modelo. Esse aqui é sobre o modelo escrevendo o encanamento. E pra quem quer o irmão direto dessa história, o post do "Claude se recusa a escrever spec, três vezes seguidas" tem o mesmo formato 3-vezes-seguidas: spec-driven development, 3 falhas.
Por que IA cai no padrão de esconder sintoma
A Stack Overflow Developer Survey de 2024 mostrou que algo em torno de 80% dos desenvolvedores profissionais usavam ou planejavam usar ferramentas de IA, e a parcela que de fato confiava na saída delas tinha caído em relação ao ano anterior. As análises que apareceram depois insistem no mesmo ponto: bug de código gerado por IA se concentra em erros de lógica e em manipulação de entrada/saída, numa densidade visivelmente maior que código humano de senioridade equivalente. O número mais citado é por volta de 1.7x de densidade de bugs, mas cada estudo mede de um jeito, então vale conferir antes de citar de cabeça.
O mecanismo não tem mistério. Um LLM prevê o próximo token mais plausível dado o contexto. "Padrão de tratamento de erro" é uma das coisas mais super-representadas no dado de treino dele. Try-catch, null-check, default no retorno, retry: estatisticamente, são as edições que mais aparecem quando alguém escreve "conserta esse erro" num repositório público. O modelo está fazendo exatamente o que foi treinado pra fazer.
O que falta é outro tipo de token. "Ainda não identifiquei a causa raiz. Continuando a investigação." Essa frase é rara no dado de treino porque humano raramente faz commit dela. A gente faz commit da correção, não do "ainda não achei". Então o modelo nunca aprendeu a default em "continua olhando".
Você tem que colocar esse token na cara dele. É pra isso que serve a próxima seção.
10 hábitos de debug → 10 prompts
Cada item vira um hábito clássico de debug. Cada um é uma frase que eu colo no prompt ou no CLAUDE.md, dependendo do quanto eu quero que vire reflexo.

1. Suspeite do input. "Antes de propor correção, confirme que os logs que você está lendo estão completos e que o monitoring que você está confiando realmente reporta o estado que você acha que reporta." Esse é o que o Claude mais pula. Diagnostica feliz em cima de log rotacionado pela metade.
2. Reproduza antes de corrigir. "Reproduza o bug localmente e mostre o passo a passo mínimo. Se não conseguir reproduzir, diga isso explicitamente e pare." O "pare" é onde tá o serviço. Fecha a porta pro chute.
3. Ache a fronteira. "Identifique a fronteira entre o comportamento que funciona e o que está quebrado. Qual o último componente que retorna dado correto?" Empurra o modelo pra parar de chutar linha a linha e passar a reduzir camada a camada.
4. Compare contra um estado bom conhecido. "Compare o código atual com o último estado funcional conhecido. Rode git log --oneline -20 e identifique qualquer mudança que plausivelmente correlacione com a janela de falha." É o prompt que faz aparecer aquele commit que ninguém lembra de ter feito.
5. Monte uma linha do tempo. "Desde quando isso falha? É súbito ou gradual? Mapeie a taxa de erro contra horário de deploy, pico de tráfego e mudança de configuração." Súbito + correlacionado a deploy é um bug. Gradual + descorrelacionado é outro bug completamente. Misturar os dois é como três "correções" se empilham.
6. Audite retry, cache e timeout. "Liste todo retry, cache e timeout no caminho. Pra cada um, descreva o que acontece quando a chamada subjacente está lenta mas não falhou." Esse aqui teria pegado o esgotamento do pool no primeiro passe.
7. Procure caminho de amplificação. "Existe algum caminho onde um erro pequeno é multiplicado? Uma chamada falhada que dispara três retries, cada um abrindo nova conexão, cada um adicionando latência pra próxima?" Se o retry storm tá escondido dentro de um autoscaler, você ganha de brinde uma instance storm.
8. Adicione observabilidade, não chute. "Se você não tem observação suficiente pra identificar a causa, proponha quais linhas de log ou traces específicos adicionar. Não proponha correção ainda." Isso converte "não sei" em "mede aqui", que é uma resposta muito mais útil que correção fake.
9. Simplifique o suspeito. "Remova componentes não-essenciais do caminho que falha até que o bug seja reproduzível na forma mais simples possível. Qual o menor input que ainda dispara o bug?" Quase sempre, o bug não tava na parte que você tava olhando.
10. Quebre de propósito. "Pra verificar uma hipótese, proponha uma mudança intencional que deveria piorar ou melhorar o bug. Preveja o resultado antes de rodar." Vira debug de observação em experimento. E pega monitoring mentindo, também.
Os 10 hábitos saem do trabalho clássico de David Agans (Debugging: The 9 Indispensable Rules, 2002) somado a uns anos de tropeço próprio com pipeline de IA. A versão "como vira prompt e como cabe no CLAUDE.md" eu fui montando incidente por incidente, e essa lista é o estado atual.
Persistir a regra no CLAUDE.md
Colar 10 frases em todo prompt não escala. O CLAUDE.md é o lugar onde regra fica morando.
O que a Anthropic recomenda, e eu repito, é manter o CLAUDE.md em algo entre 100 e 150 linhas, pra ele caber no contexto a cada turno. Gastar 12 dessas linhas com regra de debug é um bom investimento.
## Debugging Rules
- Não escreva código de correção até ter identificado a causa raiz.
- Não suprima sintoma. Se o sintoma sumiu mas a causa segue desconhecida, isso não é correção.
- Antes de corrigir, escreva um teste que falhe e que reproduza o bug.
- Depois de corrigir, rode a suíte de testes completa e reporte qualquer teste novo que falhou.
- Se três tentativas falharem em sequência no mesmo bug, pare. Resuma o que tentou, o que descartou, qual hipótese sobrou, e peça input humano.
## Debugging Workflow
1. Root Cause Investigation: lê log, trace, e o caminho do código.
2. Pattern Analysis: procura o mesmo anti-padrão em outros lugares da base.
3. Hypothesis Testing: escreve um teste que falha sse a hipótese estiver correta.
4. Implementation: só depois de 1-3 fecharem.
O detalhe importante é que isso são restrições, não instruções. "Não escreva código de correção até..." rende mais que "investigue primeiro." É o formato de restrição que segura a máquina de previsão de token de pular alegre pro próximo passo.
A história completa de como armar o CLAUDE.md, junto com hooks e MCP em três camadas, é a mesma camada de equipamento que usei pra separar um agente grande em Observer, Strategist, Marketer. Essa série é a semana de debug do mesmo arsenal.
Automatizar reflexo com hooks
CLAUDE.md é cérebro. Hooks são reflexo. Dois importam pra debug.
PreToolUse: bloqueia comando destrutivo. No meio da debug, o modelo às vezes sugere algo tipo rm -rf node_modules. Num dia ruim, sugere um DROP TABLE puro. Um hook de PreToolUse intercepta a chamada da tool Bash, faz um grep no comando contra uma denylist enxuta, e sai com exit 2 pra bloquear. O Claude Code trata exit code 2 do PreToolUse como "essa chamada foi negada, avise o modelo o motivo".
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [{
"type": "command",
"command": "if echo \"$TOOL_INPUT\" | grep -qE 'rm\\s+-rf|DROP\\s+TABLE'; then echo 'BLOCK: destructive command' >&2; exit 2; fi"
}]
}
]
}
}
PostToolUse: roda teste depois de edição. Matcher Edit|Write, command roda sua suíte de testes ou pelo menos um subset rápido. O modelo agora vê o teste falhar no turno seguinte e reage no mesmo turno em que criou, em vez de lembrar 30 mensagens depois. A referência oficial de hooks do Claude Code cobre matchers e convenção de exit code em detalhe.
CLAUDE.md, PreToolUse e PostToolUse formam a camada de equipamento de um debugger de IA. Cada peça custa quase nada. A ligação do on-call às 11 da noite, sim.
Quando 3 "correções" escondidas seguidas significam "para"
A regra mais útil, a única que teria salvado meu on-call:
Se três tentativas seguidas falharem em corrigir o mesmo bug, pare e escale.
Três não tem magia. É o ponto em que o custo de mais um chute supera o custo de admitir que o bug é estrutural. Na terceira tentativa, o modelo costuma estar fazendo pattern-matching em cima de pattern-matching, e olho humano sai mais barato que o quarto retry.
E o custo prático, em real: incidente de 2 horas com equipe de 5 pessoas é 10 pessoas-hora. A R 100 a hora, é R 1.000 por incidente. Se isso acontece 10 vezes no mês, são R$ 10.000 saindo de produtividade. Comparado com 12 linhas no CLAUDE.md, a conta fecha rápido.
"Deixa o Claude debugar" é meia verdade. Ele é rápido mesmo. Só que ele defaulta pra rápido em esconder o problema, a não ser que você arme ele diferente. Os 10 prompts armam. O CLAUDE.md lembra por você. Os hooks pegam o que escapou.
Fontes:
- 2025 Stack Overflow Developer Survey, AI section
- Closing the developer AI trust gap (Stack Overflow Blog, fev 2026)
- Claude Code Hooks reference
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev · TabNews