Por que o ChatGPT ignora o seu site (mesmo se você for #1 no Google)
Você abre o ChatGPT, faz uma pergunta sobre o tema do seu site, e o modelo cita três concorrentes. Nenhum deles tem mais autoridade que você. Nenhum deles ranqueia tão bem no Google. Mas o ChatGPT escolheu eles. Por quê?
A resposta curta: o ChatGPT não faz Google. O Perplexity não faz Google. Eles funcionam com uma lógica diferente, e o seu site provavelmente foi construído pensando em uma lógica antiga.
Esse texto é a versão de uma página de um problema que tem nome: LLMO (Large Language Model Optimization). É o que vem depois de SEO.
A diferença que ninguém te contou
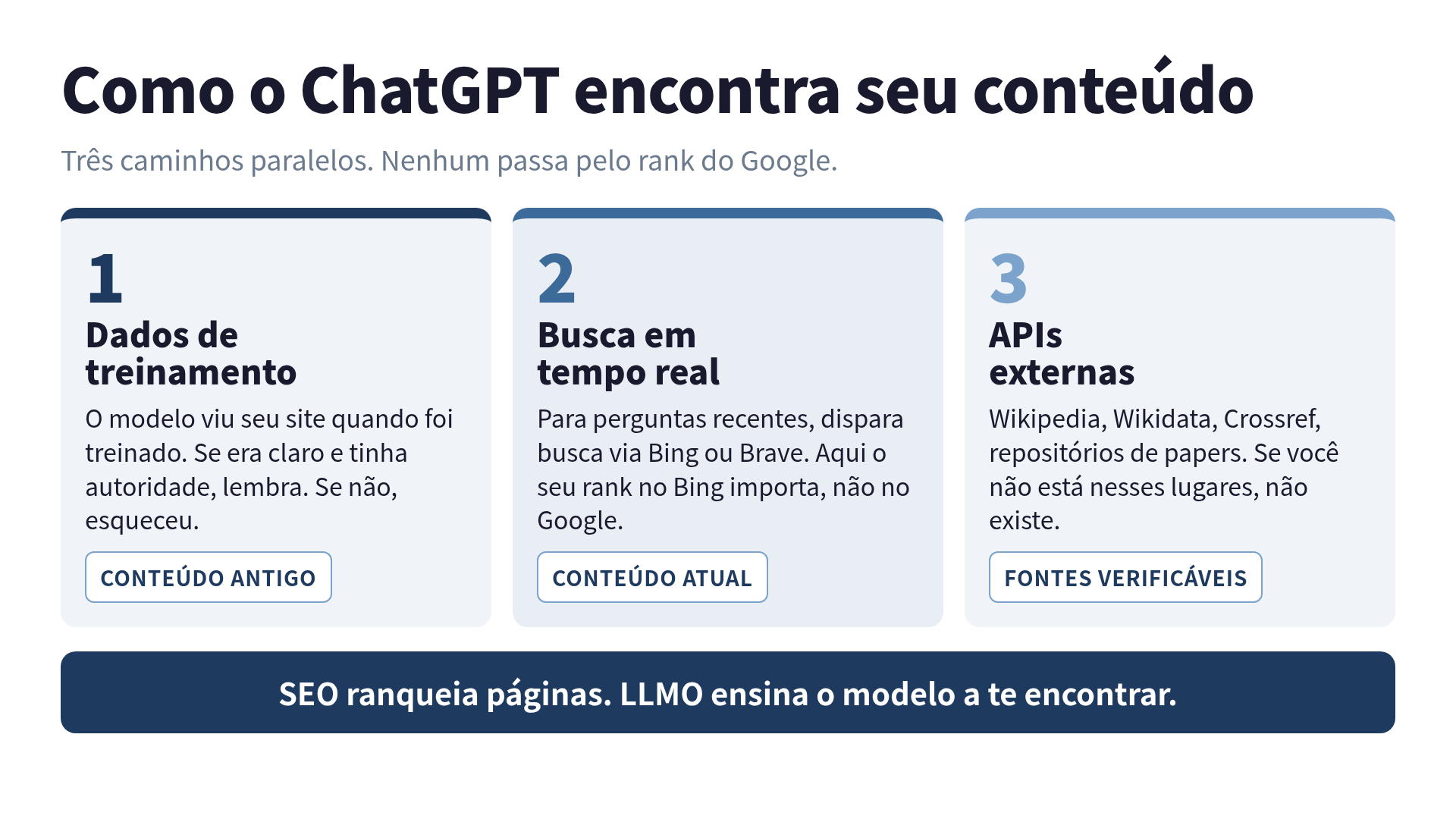
SEO foi desenhado para um robô que rastreia páginas, segue links, e ranqueia pelo PageRank. ChatGPT não faz nada disso. Ele tem três caminhos para encontrar seu conteúdo:
Caminho 1: dados de treinamento. O modelo viu seu site quando foi treinado, há meses ou anos atrás. Se o conteúdo era claro, estruturado, e tinha autoridade, o modelo lembra. Se não, esqueceu.
Caminho 2: busca em tempo real. Quando o usuário pergunta algo recente, o modelo dispara uma busca via Bing, Brave ou outro provedor, lê os primeiros resultados, e sintetiza. Aqui o seu rank no Bing importa, não no Google.
Caminho 3: APIs externas. Wikipedia, Wikidata, Crossref, repositórios de papers. Se você está nesses lugares, é citado. Se não, não existe.
Nenhum desses caminhos passa diretamente pelo "rank no Google". É por isso que SEO técnico tradicional não move o ponteiro.
O que LLMO realmente é
LLMO é o conjunto de práticas para fazer seu conteúdo ser descoberto, entendido e citado por sistemas de IA. Não é magia, não é truque. É uma reorganização de cinco peças do seu site.
As 5 peças do LLMO
1. Knowledge Clarity (clareza do conhecimento). Seu conteúdo precisa ser fácil de extrair em pedaços. Frases curtas, definições explícitas, parágrafos focados em uma ideia. O ChatGPT não lê seu site inteiro, ele extrai snippets.
2. Structural Formatting (formatação estrutural). HTML semântico, schema.org, headings em ordem, listas e tabelas onde fazem sentido. O modelo prefere estrutura previsível.
3. Retrieval Signals (sinais de descoberta). llms.txt no root do site, sitemap.xml atualizado, JSON-LD declarando o que cada página é. Sinais que dizem "olha aqui, isso é importante".
4. Authority Signals (sinais de autoridade). Backlinks de fontes confiáveis, presença em Wikipedia, citações em papers, perfil verificável. O modelo confia em quem outras fontes confiam.
5. Citation Signals (sinais de citação). Você cita fontes? Suas fontes são verificáveis? O modelo prefere conteúdo que mostra de onde tirou as informações, porque pode validar.
Isso é tudo. Não é uma lista mágica de palavras-chave. É engenharia editorial.

O caso do meu próprio site
Quando comecei a aplicar LLMO no kenimoto.dev, o efeito não foi imediato. Demorou cerca de 6 semanas para ver mudanças no tráfego vindo do ChatGPT (rastreável via parâmetro de fonte). Mas as mudanças foram permanentes.
O que fiz, em ordem de impacto:
- Adicionei
llms.txtna raiz, listando os tópicos principais e os artigos canônicos - Reescrevi a homepage em frases curtas e parágrafos focados (saí de "construímos soluções inovadoras" para "construo organizações AI-native")
- Coloquei JSON-LD
Person+Articleem cada página - Repliquei conteúdo em múltiplas plataformas (Zenn, Dev.to, Hashnode) para gerar sinais de autoridade externa
- Citei fontes em todos os artigos com links diretos
Nada disso é exótico. Mas a maioria dos sites técnicos brasileiros eu vejo ainda não faz nem o básico.
"Mas e o Google?"
Boa notícia: LLMO e SEO se reforçam. Conteúdo claro, estruturado e com autoridade ranqueia melhor no Google também. A diferença é que o LLMO te dá uma rota adicional, independente do algoritmo do Google.
Em 2025, ChatGPT, Claude e Perplexity já respondem 15-20% das buscas de informação técnica em desenvolvedores brasileiros (fonte: minha amostra informal de leitores). Em 2026 esse número vai dobrar. Sites que não estiverem preparados vão ficar invisíveis para essa fatia.
Por onde começar
Se você quer testar LLMO no seu site hoje, três coisas para começar:
- Adicione um
llms.txt(especificação). Cinco linhas listando os tópicos principais. 10 minutos de trabalho. - Coloque JSON-LD nas páginas mais importantes (
Personna homepage,Articleem posts,Bookem produtos). Use o validador do Google para verificar. - Reescreva a homepage em frases curtas. Menos jargão, mais especificidade. Um humano deveria entender em 10 segundos quem você é e o que faz. O modelo também.
Os outros dois pilares (autoridade e citação) demandam mais tempo, mas começam aqui.
Onde aprofundar
A documentação completa do framework está em llmoframework.com/pt (versão em português), com guias por plataforma (WordPress, Next.js, Astro), case studies com métricas, e referências de papers acadêmicos sobre como os modelos selecionam conteúdo para citação. É grátis.
Mas você não precisa da framework para começar. Adiciona um llms.txt, escreve duas frases mais claras na homepage, e veja o que muda em 6 semanas. É como SEO em 2010: ainda dá para se posicionar antes da maioria perceber que é uma corrida.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev · TabNews