Fiz uma ferramenta pra ver LLMs gerando texto token por token
Fala, galera!
Você já parou pra pensar no que acontece entre o momento que você manda um prompt e o momento que a resposta aparece? Tipo, qual token o modelo quase escolheu mas não escolheu? Quão confiante ele estava naquela decisão?
Foi pra isso que eu desenvolvi a Miru Tracer.
O que é
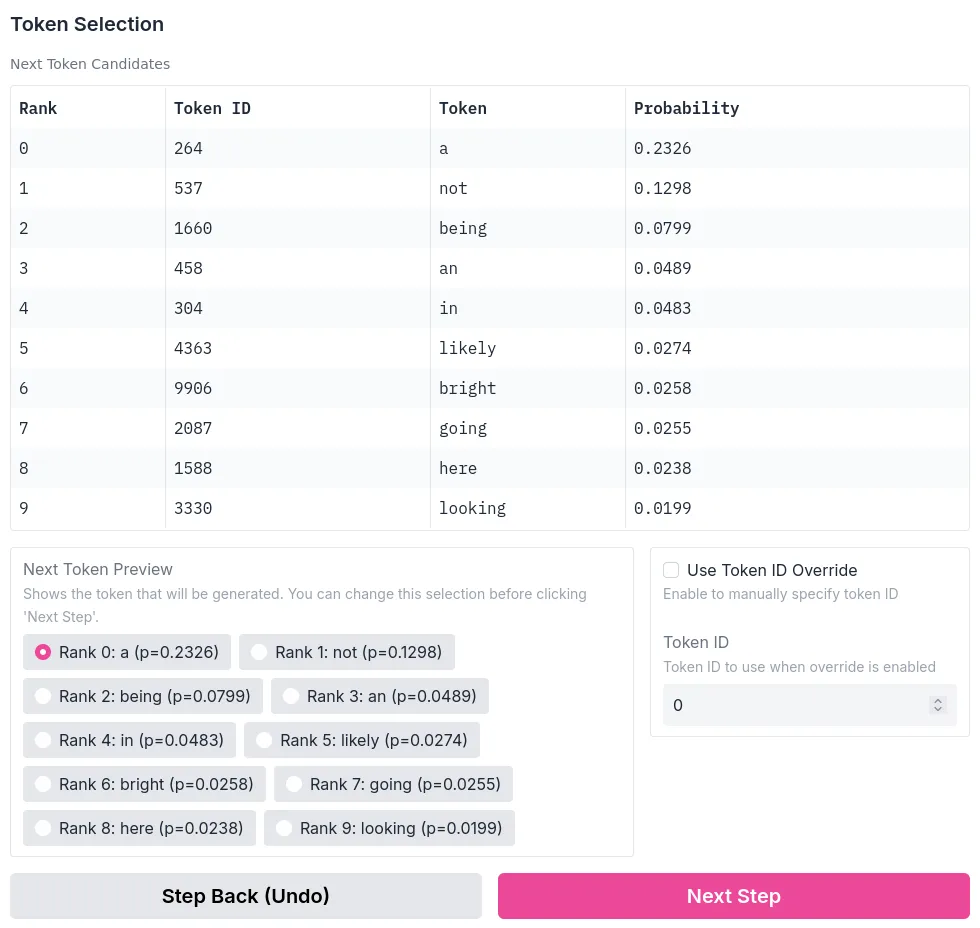
É uma aplicação Gradio que carrega modelos do Hugging Face e mostra a geração de texto acontecendo passo a passo. Você vê a distribuição de probabilidade de cada token, a confiança (por entropia), e no modo interativo pode até escolher manualmente qual token vem a seguir em vez de deixar o modelo decidir.
Não é interpretabilidade mecanicista ainda, já que não mexe em circuitos neurais nem aplica técnicas como activation steering (isso é o próximo passo). Por enquanto a ideia é só dar mais visibilidade ao processo de geração, que normalmente fica escondido.
Pra que serve
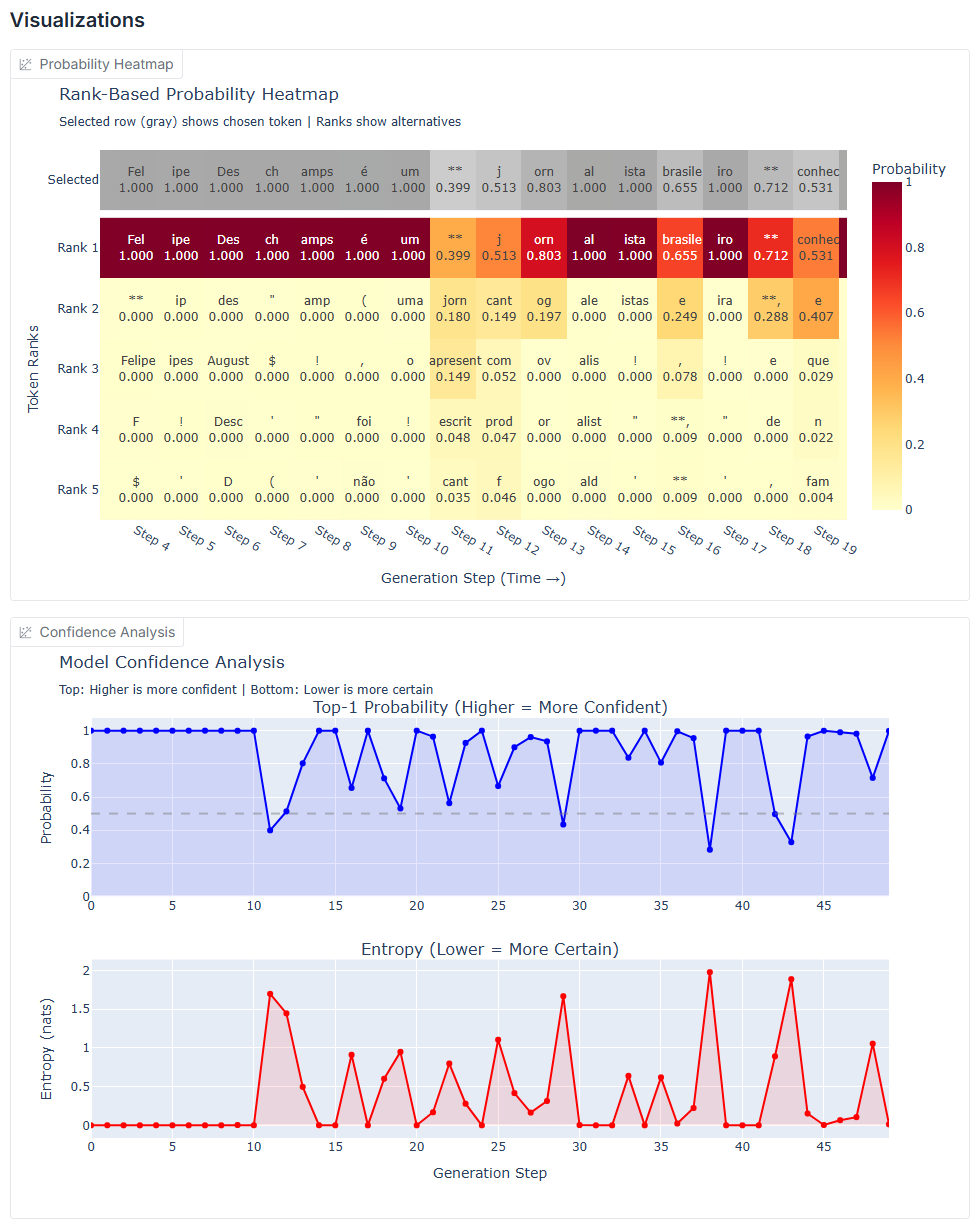
Quando você está aprendendo sobre LLMs, ler sobre temperatura e top-k é uma coisa. Ver o sampling acontecendo na sua frente, token por token, é outra completamente diferente. Se você está debugando um prompt e quer saber onde o modelo ficou "inseguro", os gráficos de entropia mostram exatamente isso. E se você só quer explorar, tipo "e se eu forçar ele a escolher esse token em vez daquele outro?", o modo interativo deixa.
O modo logging grava tudo (todas as probabilidades, todos os tokens considerados) e exporta pra JSON. Aí você pode analisar depois, fazer seus próprios gráficos, o que você quiser.
Como rodar
Clone o repo, cria um ambiente virtual, instala o requirements.txt. Mas uns detalhes: se você não tá no Python 3.13, vai precisar comentar a linha audioop-lts do requirements (é um módulo de compatibilidade que só existe/é necessário no 3.13). E se você quer rodar em GPU com CUDA, tem que instalar o PyTorch separadamente com suporte CUDA antes: o site deles tem as instruções certinhas pra sua configuração.
Pra começar a testar, recomendo o modelo Qwen/Qwen3-1.7b. É pequeno, roda em CPU tranquilo, e já dá pra entender como a ferramenta funciona sem precisar de uma placa de vídeo do caralho.
Lembrando que isso é uma ferramenta experimental em desenvolvimento ativo. Tem várias melhorias e fixes a caminho, incluindo uma imagem Docker pré-buildada pra facilitar a vida.
Por que eu fiz isso
A gente usa IA pra tudo hoje em dia, mas tem uma diferença entre "não preciso saber todos os detalhes" e "nem sei por onde começar se quiser entender". Eu queria uma ferramenta simples, visual, que qualquer dev pudesse usar pra entender melhor como esses modelos funcionam.
E é o primeiro passo de um projeto maior. A ideia é eventualmente mexer com interpretabilidade mecanicista de verdade: entender quais circuitos são ativados, como a informação flui, fazer activation steering. Mas tem que começar de algum lugar, e começar vendo o que está acontecendo na geração já é um bom começo.
O projeto é Unlicense (domínio público). Se você quiser contribuir, achou um bug, ou só quer conversar sobre isso, me chama no Telegram @rlaneth ou abre uma issue no GitHub!