Tem trabalho brasileiro aí: do workflow de pesquisa ao produto real no CorridorKey
Recentemente saiu um vídeo da Corridor Crew sobre o CorridorKey:
Clique na imagem pra abrir o vídeo
Uma das coisas mais legais, para mim, foi ver a reação da galera do Brasil nos comentários. Tinha bastante mensagem no tom de “vai Brasil”, “é nós”, “que orgulho ver um brasileiro nisso”. E isso teve um peso simbólico, claro.
Mas este texto não é sobre comemorar menção em vídeo.
Quero usar esse contexto como gancho para falar de uma parte bem menos vistosa do trabalho: a camada de engenharia que aparece quando um projeto de machine learning deixa de ser só um experimento promissor e passa a precisar funcionar de forma previsível no mundo real.
Meu recorte nesse projeto foi a trilha de runtime orientado à produção e a integração via plugin OFX para DaVinci Resolve.
Quando a gente fala de ML aplicado, a conversa costuma gravitar em torno do modelo. Arquitetura, dataset, benchmark, qualidade visual, paper, inferência. Tudo isso importa. Mas existe uma outra camada, menos fotogênica e normalmente mais decisiva: a que define se aquilo vai funcionar fora da máquina do autor, fora do ambiente de pesquisa e fora do README idealizado.
É essa camada que me interessa aqui.
Antes de tudo: os forks em Python foram fundamentais
Vale deixar isso claro logo no começo.
Eu não vejo os forks e experimentações em Python ao redor do projeto como algo que o runtime nativo “substituiu”. Não foi isso. Nem de longe.
Muito do que orientou minhas decisões veio justamente dali:
- ideias de otimização
- preferências reais dos usuários
- atritos do workflow
- trade-offs que apareceram no uso
- limitações práticas que só ficam visíveis quando várias pessoas começam a esticar o projeto em direções diferentes
Então, para mim, são propostas complementares.
O lado mais centrado em Python foi — e continua sendo — excelente para experimentação, iteração rápida, wrappers, interfaces, testes de caminho e exploração geral do espaço de solução.
O problema que eu estava tentando resolver era outro.
Eu estava menos preocupado com “como iterar rápido sobre o workflow original” e mais com perguntas como:
- como distribuir isso para pessoas que não querem montar ambiente?
- como reduzir variabilidade entre máquinas?
- como deixar explícito o que é suportado e o que é experimental?
- como diagnosticar falhas sem transformar suporte em investigação forense?
- como integrar isso a um host como o Resolve sem torná-lo refém de backend, VRAM e estado de runtime?
Quando o usuário final deixa de ser o próprio desenvolvedor, a natureza do problema muda rápido.
O momento em que “rodar o modelo” deixa de ser o centro
Enquanto um sistema vive dentro de um workflow de pesquisa, muita coisa pode ficar implícita.
Uma combinação muito específica de dependências. Um backend que funciona “bem o suficiente”. Um conjunto de passos manuais que ninguém documenta porque já virou memória muscular. Uma tolerância tácita ao clássico “na minha máquina roda”.
Isso é normal.
Mas quando a mesma solução começa a caminhar para produto, as perguntas endurecem:
- qual é o contrato operacional do sistema?
- quais caminhos de execução são reais e quais existem só em teoria?
- como garantir comportamento consistente em hardware diferente?
- como expor o estado do runtime de forma inteligível?
- como empacotar artefatos sem introduzir ambiguidade?
- como impedir que o host pague por cada erro do backend?
Nesse ponto, inferência continua importante, mas deixa de ser a história inteira.
O problema deixa de ser “como executar o modelo?” e passa a ser “como construir uma superfície operacional confiável em torno dele?”.
É aí que a engenharia fica mais interessante.
O objetivo não era “reescrever em C++ porque sim”
Seria uma razão fraca.
Eu não fui para um runtime nativo porque “C++ é mais sério”, nem por purismo técnico, nem para vender a fantasia de que reescrever algo em código nativo automaticamente o torna melhor. Não torna. Às vezes só te dá um conjunto novo de bugs, mais sofisticados e mais rápidos.
Também não faz sentido minimizar o valor do ecossistema Python. Para ML, ele continua sendo o lugar natural para muita coisa:
- experimentação
- export de modelos
- integração inicial
- prototipagem
- iteração rápida
- cola entre ferramentas
Isso é valioso. Muito.
Mas o problema que eu queria resolver já não era esse.
Eu queria reduzir dependências implícitas, tornar o caminho de execução mais previsível, controlar melhor o empacotamento, oferecer diagnósticos úteis e integrar o modelo a superfícies reais de uso — no caso, CLI e OFX — sem duplicar lógica nem espalhar comportamento crítico por vários cantos.
Em outras palavras: a meta não era “tirar Python por tirar”. Era definir uma fronteira de produto mais controlada.
Runtime primeiro, superfícies depois
Uma das decisões mais importantes foi tratar o runtime como a fronteira real do produto.
Não o plugin.
Não o CLI.
O runtime.
Isso parece uma escolha estrutural abstrata, mas tem consequência concreta.
Se cada superfície passa a carregar sua própria lógica de negócio, o comportamento deriva. Um ajuste entra em um lado e não no outro. Uma regra de fallback muda num lugar e fica antiga no outro. Tratamento de erro, seleção de backend, política de artefato, heurística de qualidade: tudo começa a fragmentar.
É assim que um sistema fica difícil de manter sem ninguém perceber exatamente quando aconteceu.
Então a ideia foi manter um núcleo compartilhado e fazer com que CLI e OFX consumissem esse mesmo comportamento base, em vez de virarem ilhas independentes.
Na prática, isso melhora várias coisas:
- consistência entre interfaces
- ownership mais claro da lógica crítica
- menor duplicação
- debugging menos caótico
- evolução mais previsível
A pergunta deixa de ser “como eu faço essa interface funcionar?” e vira “qual é o contrato do sistema?”.
Essa é uma pergunta muito melhor.
Nem todo backend existente deveria virar promessa pública
Outro ponto importante: uma codebase pode ter muita coisa “existente em código” que ainda não é, de fato, uma trilha real de produto.
Provider hook. Backend experimental. Caminho parcial. Integração incompleta. Rota de debug. Prova de conceito. Ideia futura. Tudo isso pode existir legitimamente no código.
O problema começa quando a presença técnica vira, por osmose, uma promessa pública de compatibilidade.
Esse é um dos jeitos mais eficientes de criar software confuso.
“Deveria funcionar.”
“Tem suporte em tese.”
“Funciona em algumas máquinas.”
“Tem um caminho pra isso.”
É assim que as pessoas queimam tempo e confiança ao mesmo tempo.
Para um runtime assim, eu prefiro muito mais trabalhar com trilhas curadas de execução e fronteiras explícitas de suporte.
Se algo está empacotado, validado e suportado intencionalmente, isso precisa ser dito com clareza.
Se é experimental, idem.
Se existe no código mas ainda não é uma trilha real de produto, isso não deveria virar claim silenciosa.
Menos ambiguidade. Menos folclore. Melhor software.
O host não deveria absorver cada falha do backend
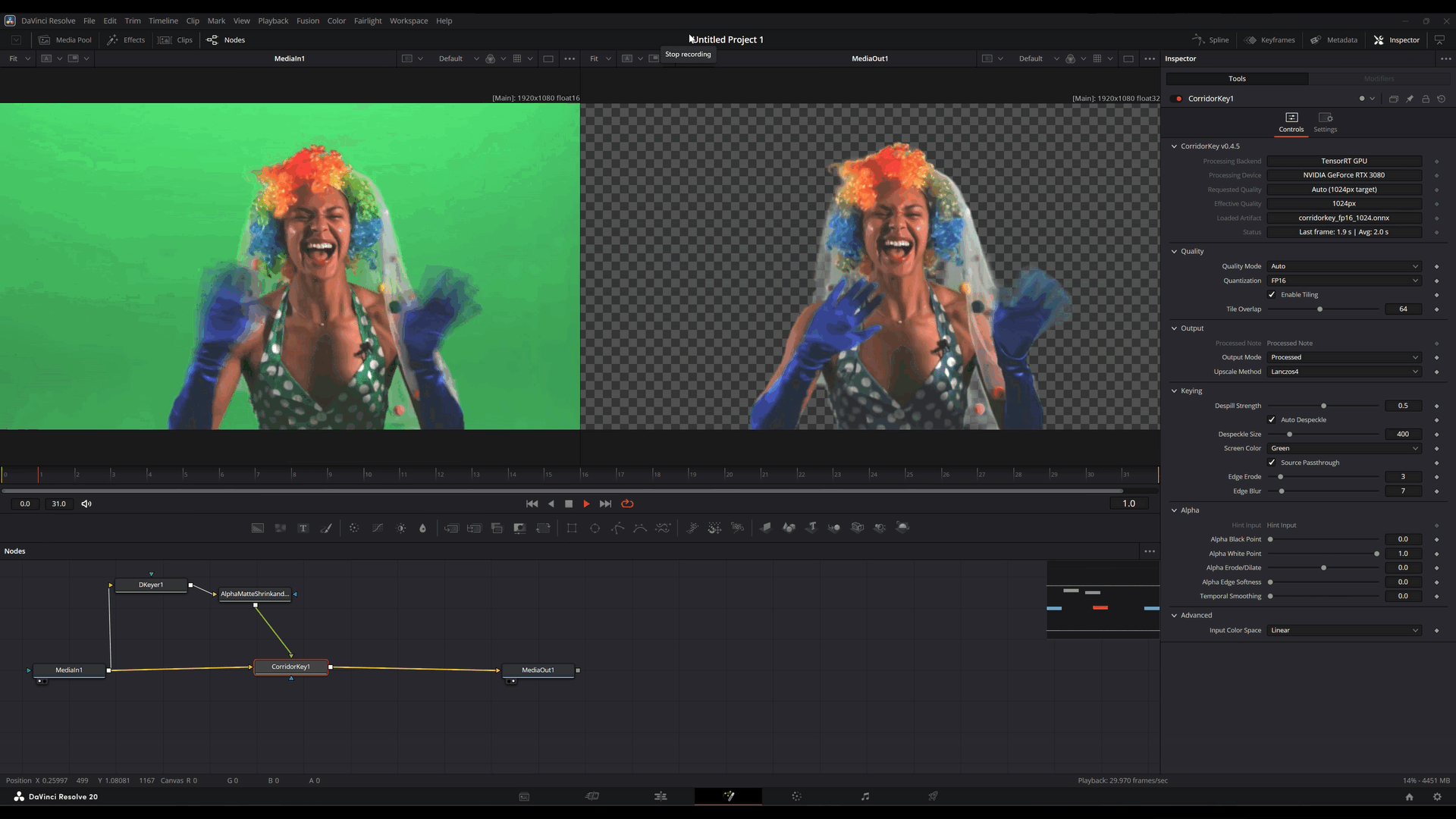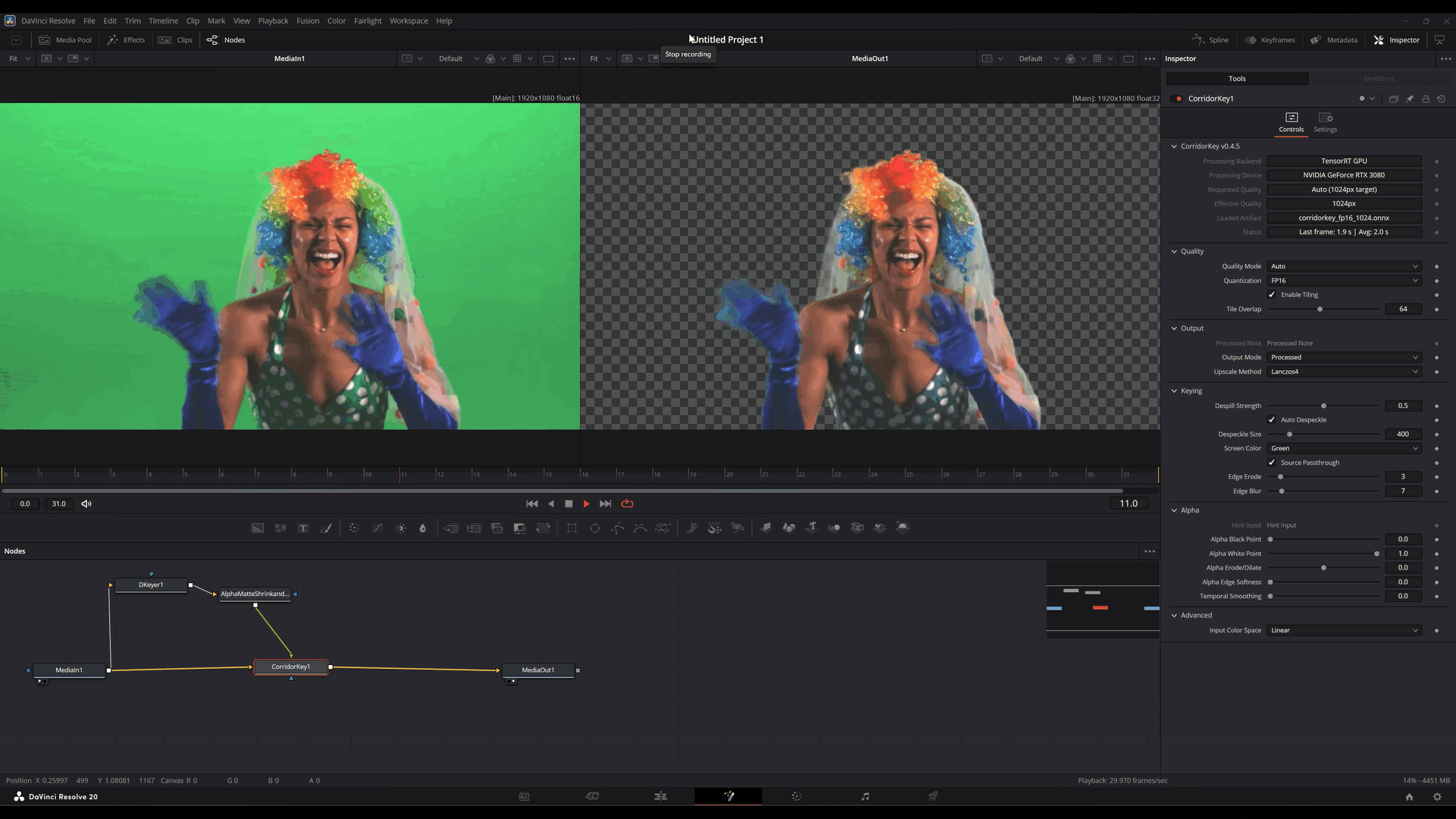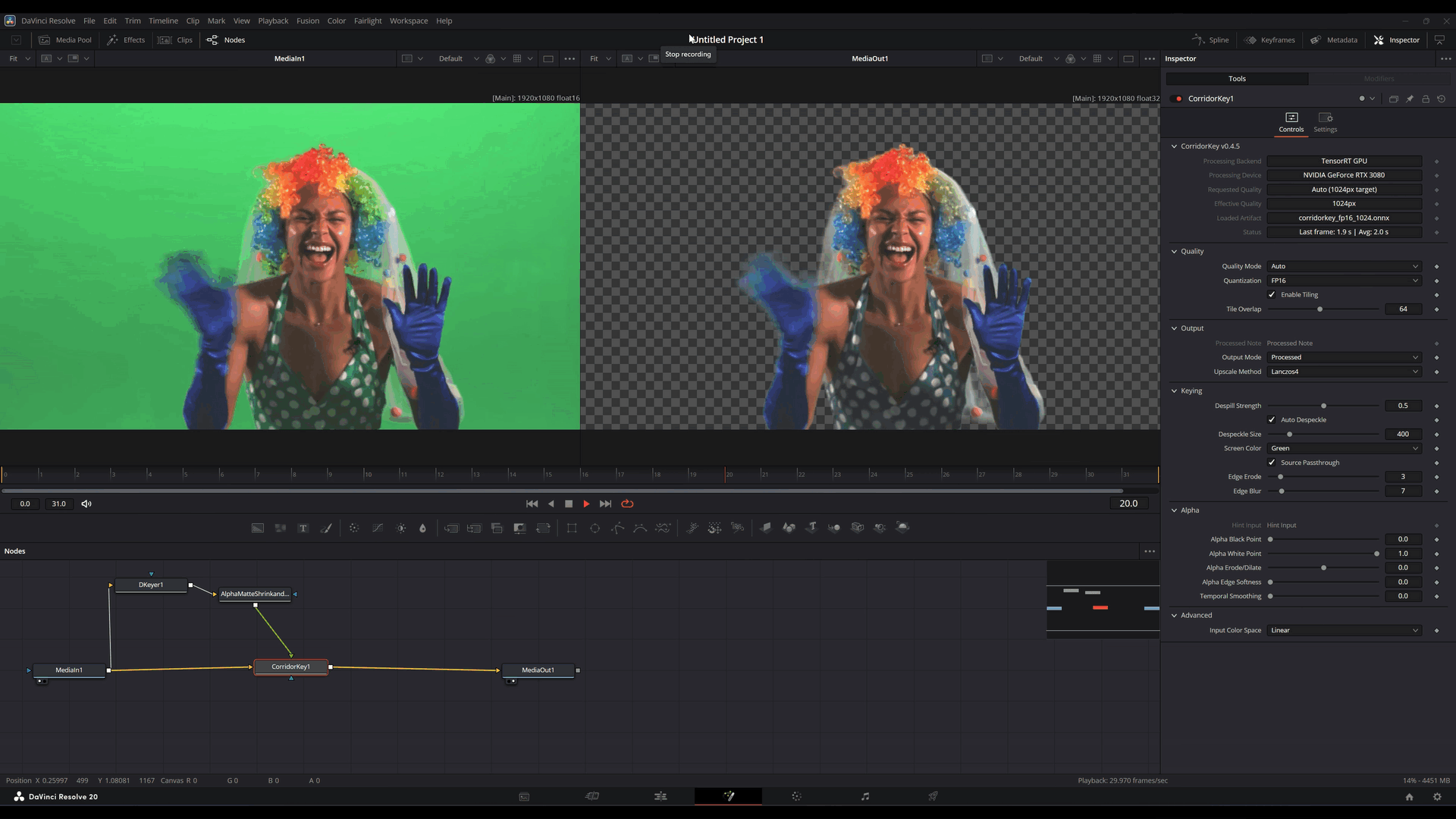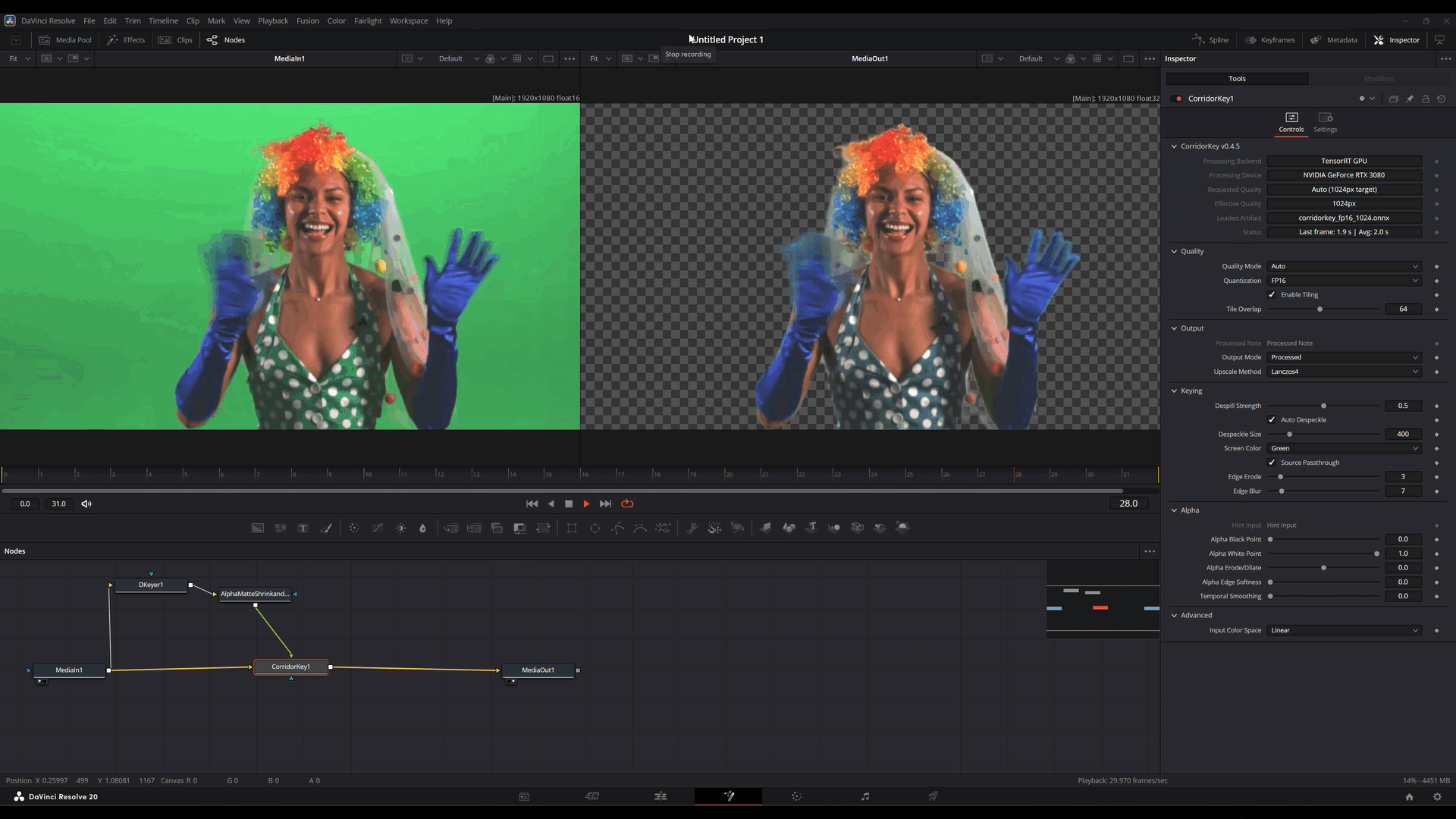
No lado do OFX, uma decisão central foi usar uma arquitetura out-of-process.
Em termos práticos: o plugin dentro do Resolve não carrega diretamente toda a responsabilidade da inferência. A parte mais pesada do runtime roda em um serviço separado, com IPC e transporte por memória compartilhada fazendo a ponte.
Isso adiciona complexidade. Sem dúvida.
Mas compra coisas importantes:
- melhor contenção de falhas
- menor risco de derrubar o host
- isolamento de problemas de backend
- tratamento mais seguro de situações de VRAM e inicialização
- controle mais claro do ciclo de vida das sessões
- reaproveitamento de sessões inicializadas entre múltiplas instâncias
Esse ponto é importante. Quando você embute ML dentro de uma aplicação grande e sensível, isolamento deixa de parecer luxo e começa a parecer engenharia defensiva básica.
Se o backend resolver falhar, a aplicação de edição não deveria morrer junto por solidariedade.
Diagnóstico não é acessório
Sistemas de ML falham de formas pouco amigáveis.
Backend indisponível. Artefato ausente. Qualidade pedida acima do que aquela GPU suporta. Fallback silencioso. Caminho experimental sendo acionado sem clareza. Inicialização parcial. Mudança de comportamento que faz sentido depois que alguém explica e nenhum antes disso.
Se o sistema não expõe essas coisas de maneira observável, cada problema vira adivinhação.
Por isso eu não trato diagnóstico como extra de suporte.
Nem fallback reporting.
Nem visibilidade do caminho escolhido pelo runtime.
Nem clareza sobre artefatos presentes, ausentes ou incompatíveis.
Isso tudo faz parte do produto.
Sem esse tipo de observabilidade, você não tem só dívida técnica. Você tem neblina operacional. E neblina operacional custa caro porque consome tempo nas duas pontas: quem usa não entende o que aconteceu, e quem dá suporte precisa reconstruir estado mentalmente.
Empacotamento também é arquitetura
Essa parte quase nunca é a favorita de ninguém. Ainda assim, é crítica.
Quando um projeto passa a exigir instaladores, bundles, runtime portátil, inventário de artefatos, validação de release e um fluxo repetível de empacotamento, essa camada deixa de ser cola operacional. Ela vira arquitetura.
Porque, se o processo aceita qualquer pasta de runtime, qualquer modelo copiado manualmente, qualquer mistura ambígua de arquivos, a inconsistência cedo ou tarde vaza para o produto.
Sempre.
Talvez não hoje. Mas vaza.
Por isso eu tendo a preferir fluxos mais rígidos:
- trilhas curadas
- artefatos certificados
- inventário explícito
- validação antes de empacotar
- falha intencional quando o estado empacotado está inconsistente
No curto prazo, isso pode parecer menos flexível.
No médio prazo, normalmente é o que evita que um release vire loteria.
Performance útil não é só throughput
Quando alguém fala “performance”, quase sempre está pensando em uma métrica só: velocidade de inferência.
Isso importa, claro.
Mas performance útil, em produto real, é mais ampla do que isso. Ela inclui:
- custo de inicialização
- warmup
- consumo de memória
- previsibilidade entre execuções
- comportamento sob hardware limitado
- overhead de integração com host
- degradação controlada quando o caminho ideal não está disponível
O caminho mais rápido no caso perfeito não é automaticamente o melhor no mundo real.
Às vezes, a forma mais valiosa de performance é a mais sem graça: a que se comporta do mesmo jeito duas vezes seguidas. A que o usuário aprende a confiar. A que não exige interpretação criativa toda vez que muda de máquina.
Pico de throughput é ótimo.
Comportamento previsível costuma ser melhor.
O principal aprendizado
A maior lição, para mim, foi esta:
transformar ML em produto quase nunca é sobre “portar um modelo”. É sobre construir um sistema ao redor dele com contrato claro, fronteiras explícitas de suporte, empacotamento confiável, observabilidade e comportamento previsível.
O modelo importa. Óbvio.
Mas o que normalmente define se aquilo vai virar uma ferramenta confiável é tudo o que está em volta:
- arquitetura
- superfície de integração
- clareza de suporte
- diagnóstico
- política de fallback
- empacotamento
- disciplina para reduzir variabilidade
É isso que separa um experimento interessante de uma ferramenta utilizável.
Fechando
A parte mais interessante, para mim, de trabalhar nesse projeto não foi simplesmente “fazer o modelo rodar”.
Foi atuar justamente naquela camada do problema que costuma receber menos atenção pública, mas que muitas vezes decide se a solução vai sobreviver fora da demo, fora da máquina original e fora da cabeça de quem a criou.
Toda vez que uma solução de IA sai do laboratório e entra num fluxo real de trabalho, ela deixa de ser principalmente um problema de modelo e passa a ser principalmente um problema de engenharia de software.
E, para mim, é justamente aí que a coisa fica mais interessante.